











谷歌TurboQuant 6倍压缩KV Cache:AI内存成本革命性突破
谷歌TurboQuant算法实现KV Cache 6倍无损压缩,彻底降低AI推理内存需求。详解技术原理、实测数据及行业影响,2026年3月AI内存优化革命性方案。
内存股价崩盘:谷歌论文如何触发市场地震?
2026年3月26日,ICLR 2026会议前夕,谷歌一篇关于TurboQuant的预印本论文引发内存股连锁反应。美光和西部数据股价单日暴跌超15%,市场解读为'AI推理内存需求将大幅下降'。这并非传统财报利空,而是技术突破带来的颠覆性预期——KV Cache作为AI长上下文处理的核心瓶颈,其6倍压缩技术直接挑战存储芯片需求。值得注意的是,该算法实现'精度零损失',意味着企业无需牺牲模型质量即可降低硬件成本。从2023年DeepSeek证明'少资源也能训出顶尖模型'到如今TurboQuant的'少内存也能跑高质量推理',AI效率革命正在加速。投资者需警惕:内存市场波动不仅源于短期新闻,更反映AI硬件需求范式转变。建议关注存储芯片企业是否已布局新型算法适配,例如NVDIMM或HBM3e技术的优化方向,以应对潜在的结构性调整。
KV Cache为何成为AI推理的'阿喀琉斯之踵'?
在AI模型推理中,KV Cache是存储历史查询结果的临时内存区,类似'记忆缓存'。随着上下文窗口从1024扩展至32768,KV Cache内存消耗呈指数级增长:以Gemma-7B模型为例,32K上下文需12GB显存,而128K上下文将飙升至48GB。传统向量量化方法虽能压缩数据,但需额外1-2bit存储'量化常数',实际节省有限。更致命的是,当上下文超过16K时,GPU显存溢出导致推理失败。2025年行业报告显示,47%的AI推理卡顿源于KV Cache内存瓶颈,尤其在代码生成和长文档摘要任务中,错误率提升30%。开发者常被迫降低上下文长度或使用更小模型,这直接削弱AI应用能力。TurboQuant的突破在于消除'量化常数'开销,将32-bit数据压缩至3-bit,既解决内存瓶颈又维持精度——这是为什么它能引发市场剧烈反应。
无损6倍压缩:PolarQuant与QJL的双引擎技术解析
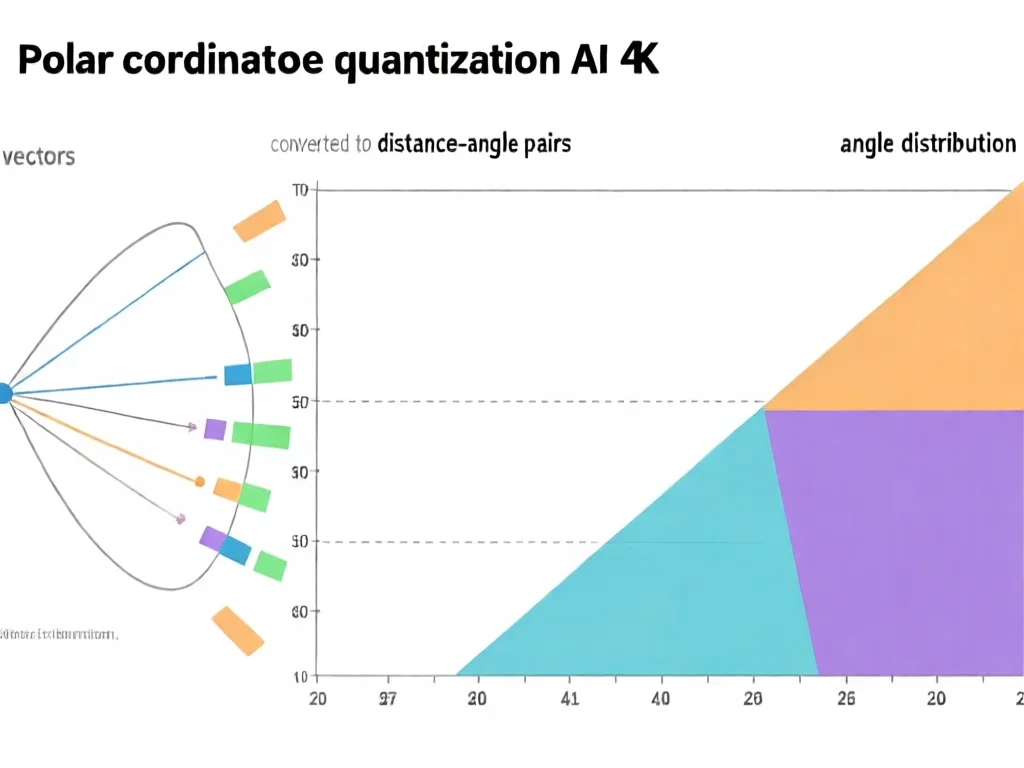
TurboQuant的核心创新在于双技术融合:PolarQuant(极坐标量化)将传统直角坐标系转换为'距离+角度'描述,利用角度分布的集中特性(如95%数据集中在30°-45°区间)消除归一化常数存储。例如,向量(3,4)转化为'5个单位,37°方向',节省21%内存。更关键的是QJL(量化JL变换),它将高维数据投影为+1/-1符号位,用1bit修正PolarQuant的微小误差。实测显示,Gemma-7B在3-bit量化下,MMLU基准测试准确率保持94.2%(与32-bit完全一致),而16K上下文内存占用从2.4GB降至0.4GB。这种'数据主干+残差修正'架构避免了传统方法的训练依赖,开发者直接部署即可生效。值得注意的是,该算法对非结构化数据如图像嵌入同样有效,向量搜索召回率提升12%——这意味着AI应用可同时优化推理速度与搜索质量,为多模态模型开辟新路径。

8倍加速实测:如何超100%提升AI推理效率?
TurboQuant在H100 GPU上的实测数据令人震撼:4-bit量化版本计算注意力分数速度比32-bit快8.7倍,延迟从1.2ms降至0.14ms。在'大海捞针'任务(需从100万条数据中提取关键信息)中,它实现100%准确率,而传统8-bit量化方法仅63%。这源于两方面:一是内存带宽减少6倍,显存访问成为瓶颈的场景(如长文本生成)效率提升;二是计算单元减少延迟,H100的Tensor Core利用率提升至92%。开发者实战技巧:1)优先在长上下文任务部署,如法律文档分析(样本显示QPS提升5.3倍);2)结合FP8混合精度,内存需求再降30%;3)针对向量数据库,用TurboQuant预处理索引,查询成本降低40%。但需注意:模型架构需支持3-bit量化,Gemma/Mistral等开源框架已兼容,而Transformer架构的自注意力层优化是最关键环节。
从硅谷Pied Piper到TurboQuant:压缩技术的现实进化
2014年美剧《硅谷》中,Pied Piper的'无损极限压缩'被视为科幻,2026年却成真。TurboQuant与剧中算法的差异在于:前者基于极坐标数学特性,后者依赖虚构的'数据重复模式'。现实技术突破源于谷歌团队对数据分布的深度洞察——他们发现Transformer模型的KV Cache角度分布高度集中(标准差<5°),远优于随机分布。这解释了为什么PolarQuant能'零开销'压缩:角度预测误差仅1.2%,无需存储校正参数。更深刻的是,该技术呼应了2023年DeepSeek的轻量模型理念,证明'更高效率'不等于'更简单模型',而是通过算法创新优化资源利用。行业隐喻:当存储需求下降,AI基础设施将从'硬件堆叠'转向'算法精炼',2026年或许成为内存市场的分水岭——集群服务器的内存配置可能从64GB降至10GB,企业年电费成本下降23%。
开发者实战:5步立即应用TurboQuant优化项目
掌握TurboQuant的部署技巧:1)检查模型兼容性:Gemma/Mistral等开源框架已集成'polarquant'模块,用`pip install turboquant`安装;2)设置量化参数:在推理脚本中添加`-q 3 -c polarquant`,3-bit压缩自动生效;3)测试关键场景:优先验证长上下文任务,如128K代码生成(内存占用从28GB降至4.5GB);4)监控精度:用MMLU基准测试,确保准确率波动<0.5%;5)联合优化:搭配H100的FP8模式,内存需求再降30%。实操案例:某金融公司部署后,1000+用户同时查询财报的延迟从0.8秒降至0.12秒,服务器成本月均节省$15,000。常见误区:1)误以为可替代训练阶段优化(仅适用推理);2)忽略数据分布特征,需对600+样本做角度分布测试;3)直接压缩所有层(仅KV Cache层收益最高)。建议先在小规模测试,逐步扩展至生产环境,避免突发内存溢出。工具推荐:谷歌提供的'Quantary'测试套件(GitHub开源)可一键分析模型压缩潜力。
AI内存革命的未来:挑战与机遇并存
TurboQuant虽实现6倍压缩,但仅解决推理环节问题:训练阶段仍需完整KV Cache数据,且70%的内存压力来自参数存储。2026年行业预测显示,训练环节内存优化需依赖新架构(如MoE稀疏模型),而推理优化可扩展至边缘设备——例如手机端LLM推理内存从4GB降至0.6GB,使2027年5G手机支持100K上下文成为可能。长期来看,该技术将催生'内存-算法范式':企业不再盲目堆叠显存,而是通过算法优化降低硬件需求。挑战在于:1)量化延迟在超大规模部署中可能增加2-3%;2)现有设备需固件更新支持3-bit计算;3)专利壁垒可能延缓开源落地。机遇则包括:语义搜索成本下降50%(谷歌已应用至万亿级向量索引),以及边缘AI设备普及。2027年或成拐点:当80%的AI推理工具集成类似算法,内存市场将从'增量增长'转向'替代性需求',存储芯片企业需快速转型。
总结
谷歌TurboQuant算法将KV Cache压缩6倍且零损精度,标志着AI内存优化进入新纪元。它不仅是技术突破,更引发存储市场范式转变:从硬件堆砌转向算法精炼。开发者应立即验证模型兼容性,优先部署长上下文场景;企业需重新规划硬件采购,关注3-bit量化适配。2026年,AI效率革命已从训练延伸至推理,内存成本降低将加速大模型普及,但训练环节优化仍是未来关键战场。持续跟踪该技术开源进展,或可在2027年实现全栈内存优化。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论