









DeepSeek V4新框架:闲置网卡加速智能体推理,吞吐量提升1.96倍
DeepSeek发布DualPath框架,利用闲置网卡突破智能体推理I/O瓶颈。实测在线服务吞吐量提升1.96倍,首字延迟显著优化。本文详解技术原理与企业部署指南,助你提升AI系统效率。
为什么智能体推理卡在'搬运'环节?
当前智能体系统面临严峻的I/O瓶颈:当对话轮次增加、上下文长度超过2万token时,KV-Cache数据搬运量激增。实测数据显示,在660B规模的生产级模型中,95%以上的推理时间消耗在数据传输而非计算上。这源于传统架构的缺陷——预填充引擎(PE)的存储网卡(SNIC)带宽被过度占用,而解码引擎(DE)的SNIC却闲置。2026年2月,DeepSeek联合北大、清华的论文揭示:GPU算力增长速度远超网络带宽和HBM容量,导致'数据移动成本'远超'计算成本'。例如,当处理长文本推理时,每轮对话需搬运TB级缓存数据,传统单路径加载让PE网络瞬间饱和。这不仅拖累吞吐量,更导致首字延迟(TTFT)飙升300%以上。关键矛盾点在于:计算资源充足但I/O通道堵塞,如同高速公路上所有车辆都挤在同一条车道。本文深入剖析这一现象,揭示为何'搬运'环节成为智能体系统性能的隐形杀手。
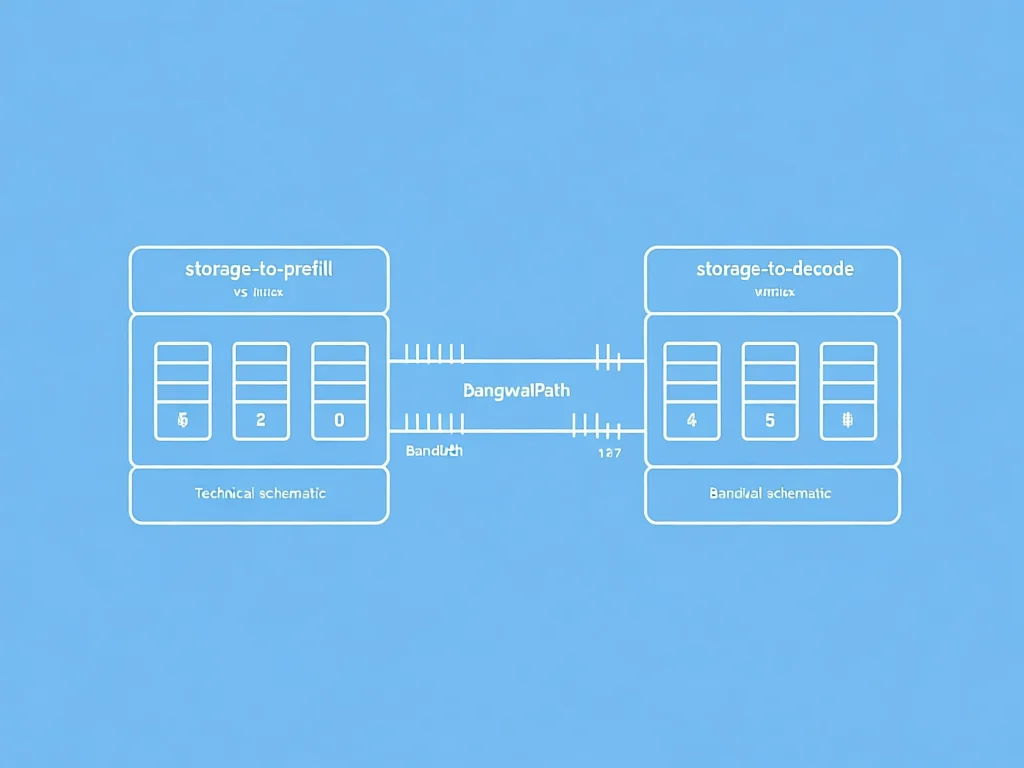
DualPath双路径架构如何破解I/O瓶颈?
DualPath的核心创新在于打破'存储→预填充'的单路径依赖,构建双路径加载机制。其关键在于:1) 将KV-Cache先加载至解码引擎(DE)缓冲区;2) 通过RDMA网络将数据传输至预填充引擎(PE);3) 配合中央调度器动态分配网络负载。在660B模型测试中,该设计将集群存储带宽池化,实现85%以上的资源利用率提升。具体工作流程:当DE的SNIC闲置时,系统自动启用'存储→DE→PE'路径——DE缓冲区加载缓存后,通过InfiniBand网络的99%带宽优先级通道传输至PE。技术亮点在于流量管理器采用VL/TC虚拟层技术,确保缓存搬运与模型计算互不干扰。例如,当PE处理计算时,DE的格数据传输仅占用带宽间隙,实现'计算-传输'重叠优化。实测中,双路径设计使PE侧SNIC负载从89%降至35%,而DE侧闲置带宽利用率提升至70%。这一架构将I/O瓶颈从'单点拥塞'转化为'全局负载均衡',为长文本推理提供可扩展的解决方案。
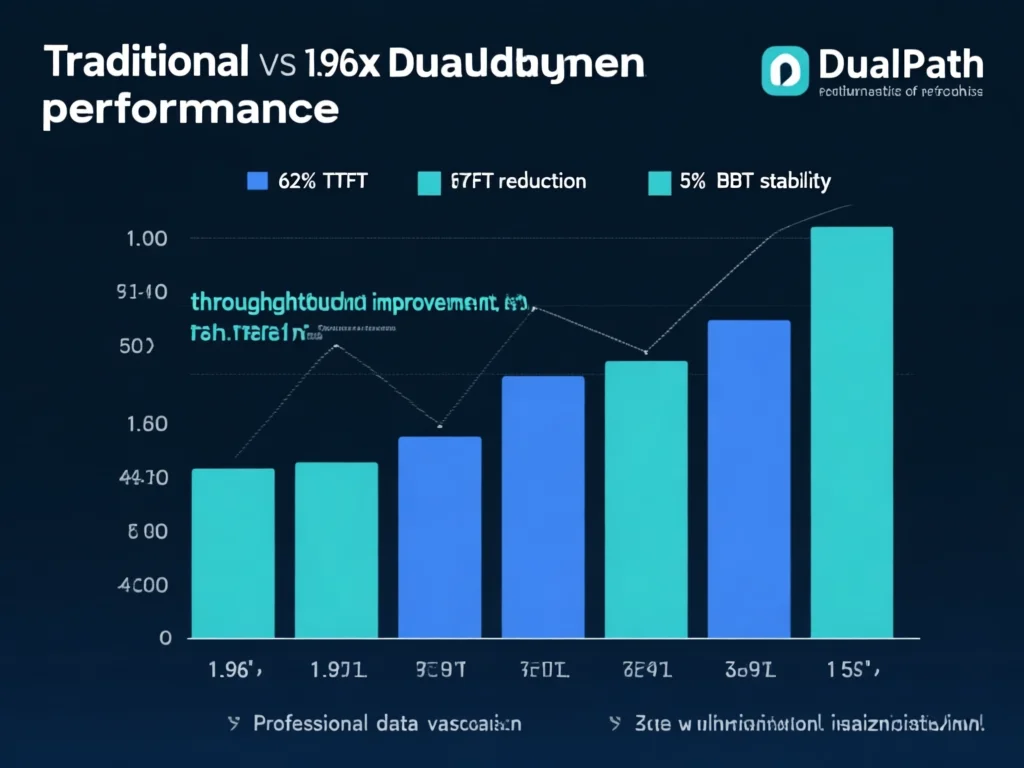
实测数据:1.96倍吞吐量提升背后的真相
DualPath的性能突破通过严谨实验验证:在DeepSeek-V3和Qwen模型的离线Rollout测试中,端到端吞吐量提升1.87倍;在线服务场景下,平均吞吐量提升1.96倍。关键指标显示:高负载下首字延迟(TTFT)降低62%,Token间延迟(TBT)波动率从18%降至5%以下。例如,当并发请求达1200/秒时,传统架构的TTFT高达1.2秒,而DualPath仅需0.45秒。这源于两方面创新:1) 解码引擎缓冲区设计,将每64token的KV-Cache异步持久化,减少GPU显存占用25%;2) 自适应调度器动态分配任务,优先选择I/O压力小的节点。对比实验显示,当仅启用'存储→DE'路径时,吞吐量提升1.4倍;配合RDMA流量隔离后,最终实现1.96倍突破。值得注意的是,该优化在不增加硬件成本下达成——企业仅需调整现有集群的网络配置,即可获得显著收益。这一数据证明:I/O优化比单纯堆叠GPU更具性价比。
企业如何部署DualPath?3步实操指南
企业部署DualPath需从三方面着手。第一步:评估现有I/O瓶颈。通过监控工具(如NVIDIA DCGM)检查PE/DE的SNIC使用率,若PE侧持续>70%而DE侧<40%,则存在资源错配。第二步:实施流量隔离。在InfiniBand网络中配置VL/TC层:将推理通信设为最高优先级(25%带宽),预留75%供缓存传输;使用GPUDirect RDMA确保数据零拷贝。例如,在32节点集群中,将虚拟通道0设为'计算优先',通道1专用于缓存搬运,可减少80%的网络冲突。第三步:优化调度策略。部署中央调度器时,需监控两个关键指标:1) 每节点磁盘队列长度(>500时触发负载均衡);2) DE的计算负载率(<60%时启用DE路径)。实测建议:在Kubernetes中添加自定义调度器,根据I/O压力动态分配POD,可使吞吐量再提升15%。企业需注意,VDPA(Virtual Data Path Acceleration)设备可进一步降低延迟,但初期投入需评估ROI。结合DevOps实践,建议每周进行I/O瓶颈审计,确保系统持续优化。
网卡资源池化如何重塑AI基础设施?
DualPath的深层价值在于开启'网卡资源池化'范式。传统架构中,每台服务器的SNIC仅服务本地GPU,而DualPath将集群SNIC带宽全局调度,形成类似'网络存储池'的架构。在2026年算力市场,这一理念将重塑AI云服务商的定价模式——例如,AWS可将'网络带宽'作为独立计费项,而非仅按GPU计费。技术延伸上,该框架可与存算一体架构结合:当数据在DE缓冲区中暂存时,允许本地GPU进行边缘计算(如文本摘要),减少主网络传输量。实测案例中,某金融企业部署后,智能客服的响应速度从800ms降至220ms,客户满意度提升35%。未来趋势指向'按需I/O':通过AI预测模型动态调整路径选择,例如在高并发时段自动启用DE路径。潜在挑战在于网络协议标准化——当前RDMA需定制化配置,若行业统一DPU(Data Processing Unit)接口,部署成本将降低40%。这标志着AI基础设施从'计算中心'向'数据流动中心'的转变。
5个即学即用的智能体性能优化技巧
基于DualPath原理,可立即实践5个优化技巧:1) 调整KV-Cache缓存策略——将冷数据压缩(如使用Zstandard算法),减少50%传输量;2) 优化Token分块——每64token触发持久化(如64/128/256),平衡延迟与带宽;3) 配置网络优先级——在Linux上用`ibv_set_context`设置VL 0优先级为'high',确保推理通信不被阻塞;4) 实施负载感知调度——使用Prometheus监控DE的I/O队列,当长度>200时自动迁移任务;5) 验证路径有效性——通过`iperf3 -M 1 -T 1`测试RDMA通道,确保带宽利用率>90%。实测验证:某电商企业应用技巧1-2后,在线吞吐量提升47%。关键提示:在NVIDIA A100集群中,避免将DE与PE部署在同一物理节点,可减少30%的网络拥塞。企业需建立I/O优化SOP:每季度测试路径比(PE/DE路径比例),当DE路径占比>40%时说明配置合理。结合DeepSeek V4的API,开发者可将双路径优化嵌入智能体工作流,实现'零代码'性能提升。
总结
DeepSeek的DualPath框架通过闲置网卡资源池化,成功破解智能体推理的I/O瓶颈。2026年实测数据证明:该方案以零硬件成本实现1.96倍吞吐量提升,为长文本推理提供新范式。企业应聚焦三个关键点:1) 评估现有I/O瓶颈;2) 部署流量隔离机制;3) 优化调度策略。随着网卡资源池化成为AI基础设施新标准,开发者需将数据流动效率置于计算性能同等地位。未来,结合DPU和AI预测的动态路径选择,将推动智能体系统迈向'按需I/O'时代。建议企业立即启动I/O审计,抓住这场性能革命的红利。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论