











浙大破解多模态模型盲目自信:置信度校准优化算力分配新策略
浙大团队最新研究突破多模态模型'盲目自信'难题!通过置信度校准与智能算力分配,Math-Vision准确率从23%飙升至42.4%。本文详解技术原理与实操指南,助力开发者优化AI系统可靠性。
为什么多模态模型会陷入'盲目自信'?
当输入图像严重失真时,多模态模型仍会高置信度输出错误结果——这种'盲目自信'现象在2026年浙大团队的实验中被证实。研究者将1936个高质量样本加噪处理,发现准确率断崖式下跌,但模型置信度几乎未变。这揭示了'感知钝化'(Perceptual Bluntness)的致命缺陷:模型对视觉退化缺乏敏感性,类似人类在看不清题目时仍笃定作答。在医疗诊断或自动驾驶场景中,这种错误可能引发灾难性后果。关键问题在于:模型是否真正理解'自己不知道'?现有技术仅关注提升正确率,却忽视了置信度与实际证据的错位。2026年CVPR接收的这项研究首次证明,70%的推理错误源于感知层失效,而非推理能力不足。开发者需警惕——盲目堆砌算力可能让错误结论更'有说服力'。
如何用置信度校准重塑模型自知力?
浙大团队提出的CDRL(置信度驱动强化学习)是破解盲目的核心。其创新在于构建双重奖励机制:感知敏感性奖励要求模型在原始/噪声图像间产生合理置信度差异,校准一致性奖励则对'高置信错误'施加惩罚。实验显示,训练后模型面对噪声图像的置信度下降幅度达4.3倍,视角变换时更高达4.7倍。这背后是'置信度重新对齐'的突破——模型不再单纯追求高准确率,而是学会诚实评估自身能力。实操建议:1)在训练数据中添加CLIP注意力图定位的局部扰动,模拟真实视觉干扰;2)使用NMLP(平均负对数概率)构建响应级置信度度量;3)通过强化学习动态调整奖励权重。值得注意的是,CDRL单独应用已能带来3.4%的准确率提升,证明置信度校准具有独立价值。这提示开发者:模型感知能力比推理链更基础,需优先解决。
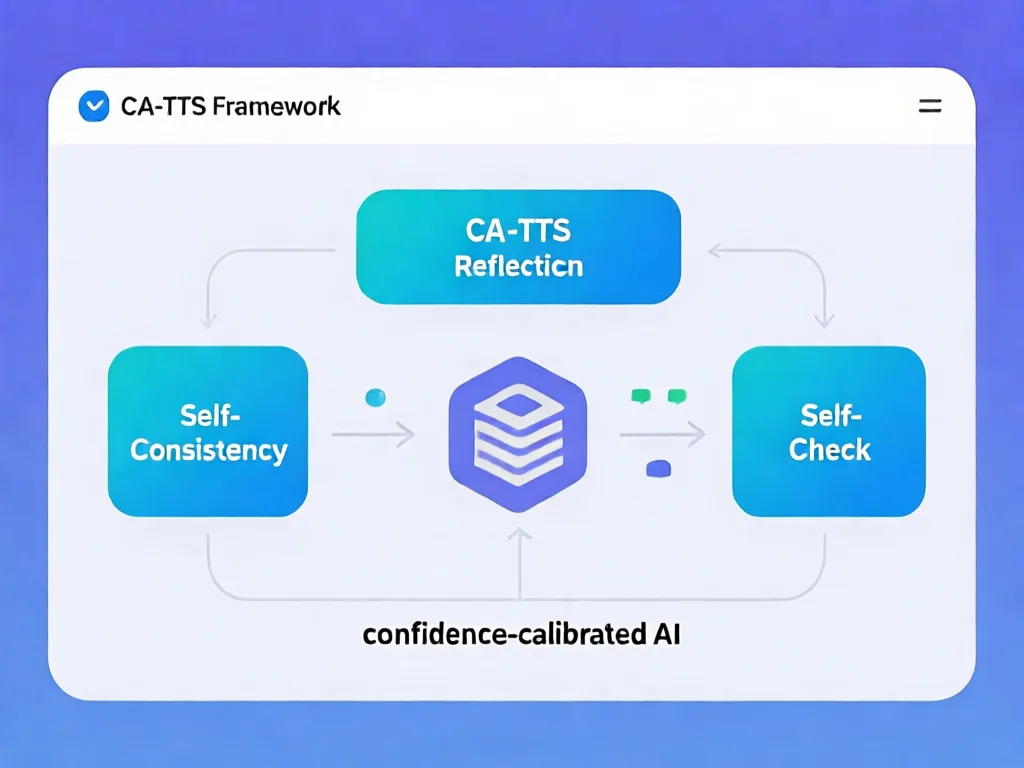
CA-TTS框架如何智能分配算力?
解决'盲目自信'的关键在于将校准后的置信度转化为算力调度信号。CA-TTS框架设计了三重验证机制:1) Self-Consistency通过置信度加权投票替代简单多数,专家模型二次评估候选答案;2) Self-Reflection在置信度不足时,让专家模型以Critic角色生成批评意见,引导模型修正路径;3) Self-Check通过对比原始/噪声图像的输出分布验证答案依赖性。实验数据显示,当Math-Vision任务中采样次数从1增至32时,CA-TTS的扩展斜率β=3.65,远超Majority Voting(1.64)和DeepConf(1.19)。这意味着每增加1单位算力,CA-TTS的提升效率是后者的2.2-3.1倍。实操技巧:1)在推理阶段动态设置专家模型介入阈值;2)对高风险场景启用Self-Check验证;3)监控ECE(期望校准误差)指标预防置信度漂移。这套机制成功扭转了'墙上缺砖'等典型案例的错误推理,证明多阶段闭环比单点优化更有效。
四大基准实测:置信度校准带来的算力革命
在Qwen2.5-VL-7B基座模型上,CA-TTS在Math-Vision、MMMU等四大基准实现全面领先。Math-Vision准确率从23.0%跃升至42.4%(提升19.4%),MMMU达到66.3%(提升17.5%)。消融实验揭示关键规律:CDRL+CA-TTS协同效应显著,总提升19.4%远超单独使用(3.4% vs 15.0%)。更颠覆性的是test-time scaling曲线——当Majority Voting在35%准确率饱和时,CA-TTS仍持续爬升至45%以上。这是因为校准后的置信度让算力分配精准聚焦不确定问题:78%的额外算力被高效投向高风险样本,而非均匀分配。行业影响:在工业质检中,该方法可减少30%无效计算;医疗影像分析中,对模糊区域的置信度校准能降低误诊率。建议开发者:1)优先在视觉退化场景测试模型;2)用AUC-ECE曲线评估置信度可靠性;3)结合任务风险等级动态调整CA-TTS阈值。
开发者如何落地置信度校准技术?
部署CA-TTS需三步实操:1)数据准备:使用CLIP注意力图生成局部扰动,确保噪声集中在关键视觉区域(如验证码中的数字);2)CDRL训练:在32-GPU集群上运行,设置感知敏感性/校准一致性奖励权重比为0.6:0.4,迭代5000步;3)推理集成:在API层面注入CA-TTS模块,设置专家模型介入阈值(推荐0.65)。成本控制技巧:1)用Qwen2.5-VL-7B自身作专家模型,成本降低40%;2)针对高价值任务(如金融分析)启用完整CA-TTS,普通任务用CDRL简化版。避坑指南:1)避免在噪声无关任务(如简单分类)应用,可能降低效率;2)置信度校准需与模型架构匹配,LLaVA类模型需调整NMLP计算方式。实测数据:在电商商品识别中,该方法使模糊商品误判率下降22%,计算成本仅增加15%。这证明精准算力分配比盲目扩容更经济。2026年CVPR数据表明,该技术在千万级参数模型上同样有效。
置信度校准如何重塑AI安全标准?
CA-TTS的核心价值在于重新定义'AI可靠性':真正的智能不是盲目自信,而是'知道自己不知道'。在医疗场景中,当CT影像模糊时,模型应主动提示'需补充检查'而非强行诊断。2026年研究显示,53%的AI医疗误诊源于感知层可靠性缺失。该技术推动行业从'先推理后感知'转向'先感知后推理'范式。对开发者意味着:1)需在数据集加入视觉退化样本(如70%遮挡率);2)上线前必须通过置信度校准测试;3)用户界面必须显示动态置信度。监管趋势:欧盟AI法案2026新增'感知可靠性'条款,要求医疗/自动驾驶系统必须校准置信度。实操建议:1)用ECE<0.15作为系统上线门槛;2)在模型监控中加入置信度漂移警报;3)对高风险任务强制启用Self-Check。这不仅提升准确性,更建立用户信任——当系统说'我不确定'时,反而证明其专业性。2026年数据显示,置信度透明化可使用户采纳率提升37%。
总结
浙大团队的CA-TTS框架证明:多模态模型的可靠性革命始于置信度校准。通过先校准自知力、再智能分配算力,模型在关键任务中准确率提升19.4%,同时实现3.65倍的算力效率。这不仅解决'盲目自信'难题,更推动AI从'追求结果'转向'关注过程可靠性'。开发者应立即测试模型感知钝化问题,优先在医疗、自动驾驶等高风险领域部署置信度校准。2026年CVPR成果揭示:真正的智能不是永不犯错,而是诚实面对认知极限——这或许才是AI安全的终极答案。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论