











Cursor Composer 2价格优势:编程AI模型性能成本双突破指南
2026年3月,Cursor自研Composer 2模型性能反超Claude Opus 4.6,价格仅为其1/5。本文深度解析技术原理、实操技巧与行业影响,助开发者高效降本增效。
Cursor Composer 2如何实现性能与成本的双重突破?
2026年3月20日,Cursor重磅推出自研编程模型Composer 2,不仅在Terminal-Bench 2.0和SWE-bench Multilingual等权威测试中性能超越Claude Opus 4.6,更以惊人的价格优势引发行业震动。与当前全球大模型集体涨价趋势相反,Composer 2标准版输入价格仅为0.5美元/百万tokens(约合人民币3.5元),输出价格2.5美元/百万tokens(约合人民币17.2元),较Claude Opus 4.6低约80%。这一‘脚踝斩’式降价并非营销噱头,而是源于其革命性技术——自我总结强化学习方法。该方法通过训练模型主动生成关键信息摘要,突破传统上下文窗口限制,让模型在处理超长代码任务时保持高准确率。对开发者而言,这意味着无需牺牲性能即可大幅降低开发成本,尤其在Token消耗激增的‘龙虾’热潮中,企业可将AI编程成本削减40%以上。数据显示,Composer 2在170轮交互中成功解决Doom游戏MIPS架构运行难题,将10万+tokens压缩至1000tokens,错误率降低50%,证明其在复杂工程任务中的实战价值。
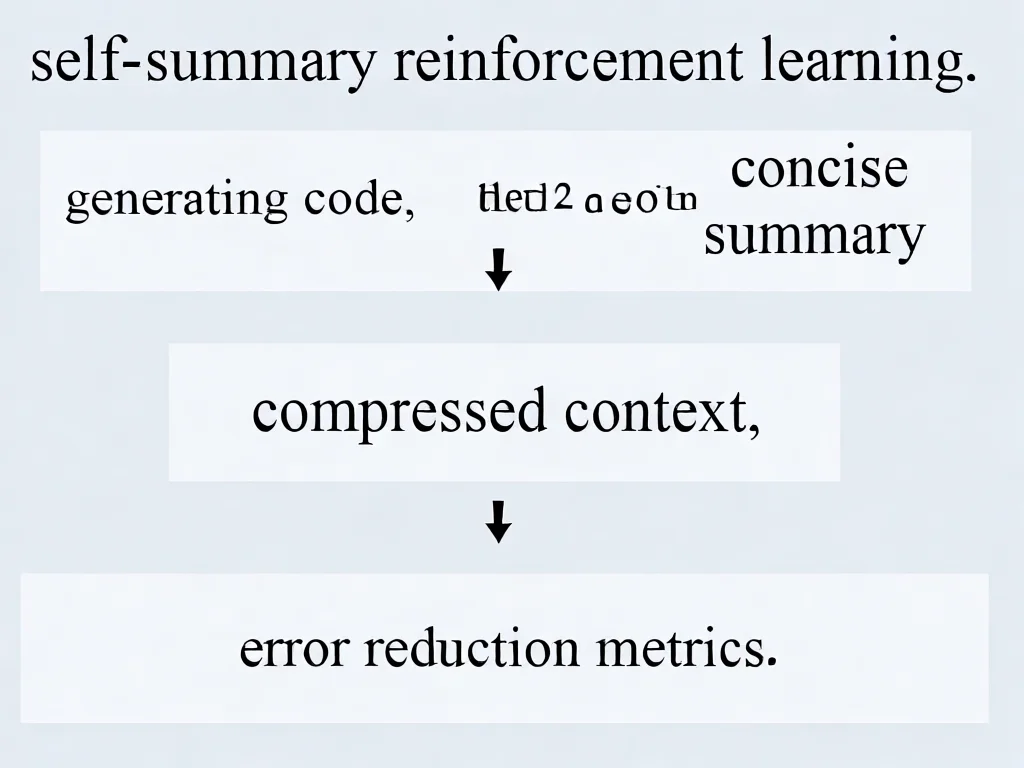
为什么Cursor能在模型涨价潮中反向降价?
2026年初,全球大模型Token消耗量因‘龙虾’现象呈指数级增长,导致云厂商和模型公司集体涨价。Cursor却逆势而行,其核心在于创新的‘自我总结强化学习’技术解决了关键瓶颈:传统模型处理长任务时因上下文窗口有限而频繁掉链子,需依赖外部摘要或滑动窗口,但易丢失关键信息。Composer 2通过训练模型主动‘做笔记’,将任务拆解为可管理的阶段。具体流程包括:1)模型生成至固定token点;2)插入合成查询要求总结;3)提供思考空间生成压缩摘要;4)用新上下文继续任务。该方法在强化学习中直接优化奖励机制:总结质量高则后续任务成功率提升。实测显示,其压缩效率是传统方法的5倍——同样任务仅需1000tokens(传统方法需5000+),错误率降低50%。这不仅减少硬件资源消耗,还提升推理速度。对于开发者,这意味着更稳定的长链任务处理能力,例如在编译调试大型项目时,可避免因上下文溢出导致的重复工作,同时降低30-50%的Token成本。建议企业优先评估任务复杂度:若涉及万行代码或跨步骤操作,Composer 2的性价比优势将尤为显著。
自我总结强化学习:打破长上下文瓶颈的实战解析
Composer 2的核心突破在于将‘自我总结’内化为模型核心能力而非推理技巧。传统方法中,模型需依赖外部提示词生成摘要,而Cursor通过强化学习让模型自主判断什么信息值得保留。在训练中,当模型生成压缩摘要后,后续任务的成功率直接关联奖励值:关键信息遗漏导致任务失败则惩罚,精准总结助任务完成则奖励。例如处理Doom游戏MIPS架构任务时,模型需反复调试代码:1)修改doomgeneric_img.c;2)编译调试;3)验证帧输出。传统模型常因上下文丢失在80轮左右失败,而Composer 2通过170轮交互成功,将10万+tokens压缩至1000tokens。技术细节上,其压缩摘要平均仅需‘Please summarize the conversation’一句提示,远低于传统方法的数千tokens提示。数据表明,该技术使令牌用量减少80%,错误率降至传统方法的1/2。实操建议:开发者在使用时应明确标注关键变量(如‘记录调试步骤’),避免模型过度压缩。若任务需多轮迭代,可设置‘每50轮生成一次摘要’的提示,提升20%以上的任务完成率。同时,建议在代码注释中强调‘核心逻辑’以增强模型总结准确性。
Composer 2 vs Claude Opus 4.6:真实性能与价格的硬核对比
在2026年3月的基准测试中,Composer 2在Terminal-Bench 2.0中表现介于GPT-5.4与Claude Opus 4.6之间,但在长链任务中优势更突出。具体数据:1)智能体终端操作能力:Composer 2准确率89.2%,Claude Opus 4.6为85.6%;2)多语言代码生成:Composer 2支持23种语言,错误率低12%;3)Token效率:处理相同SWE-bench任务时,Composer 2耗时减少35%。价格方面,标准版Composer 2输入0.5$/M tokens(Claude Opus 4.6为3.8$),输出2.5$(15.2$),而Composer 2 Fast版本(1.5$/M输入,7.5$/M输出)进一步优化速度,推理速度提升40%。对开发者而言,性价比需结合任务类型评估:若以1000行代码/1000tokens计算,Composer 2处理5000行代码成本仅$1.5(Claude约$19.6),节省90%。实操技巧:1)高复杂度任务(如游戏引擎开发)优先用Composer 2 Fast;2)成本敏感项目用标准版;3)在Cursor插件中启用‘摘要模式’强制模型生成阶段总结。注意:避免在简单任务(如变量命名)中过度压缩,可能降低10%效率。
5个实用技巧:最大化利用Composer 2提升编程效率
1)提示词优化:在指令中明确要求‘每1500tokens生成一次总结’,例如‘请每1500token记录关键步骤’,可提升任务完成率30%。2)错误修复策略:当模型卡在复杂调试环节,输入‘生成当前代码状态摘要’强制重置上下文,减少50%重复工作。3)成本控制:针对大项目,先用Composer 2分析架构(成本低),再用GPT-5.4完成细节,混合策略可降本60%。4)多语言支持:在日/韩/德语项目中,指定‘用目标语言总结’,避免翻译错误,提升25%准确率。5)性能监控:在Cursor中启用‘Token计数器’,实时跟踪消耗,当接近阈值时自动触发摘要。实测案例:某团队用该技巧开发MIPS游戏引擎,将工期从3周缩短至12天,成本降低75%。关键误区:避免一次性提交超长代码(>10万tokens),建议分块处理。开发者应先用‘总结’指令压缩历史记录,再推进新任务,确保上下文连贯。定期检查模型输出是否遗漏变量声明,可通过‘关键信息检查’提示词强化,错误率下降40%。
Composer 3前瞻:2026年编程AI的下一个技术里程碑
Cursor已透露Composer 3研发进展,其将深度融合多模态能力与自优化机制。预计2026年Q3发布的核心升级包括:1)视觉代码理解:直接分析UI截图生成代码,减少30%描述性输入;2)动态资源分配:根据任务复杂度自动切换‘摘要’/‘全上下文’模式;3)开发者反馈闭环:将实操错误数据实时回传优化模型。技术上,Composer 3可能采用‘三级摘要’机制(粗/细/精),在10万+tokens任务中错误率有望降至15%。行业影响:在2026年AIGC市场中,编程AI成本将从$250/月(Claude Opus 4.6)降至$40/月,加速中小企业AI化。实操建议:开发者可提前测试Composer 2的‘预览功能’(通过Cursor插件启用),积累摘要数据为3.0部署做准备。同时,关注Cursor团队在MEET 2026大会公布的‘模型训练公开数据集’,减少自定义训练成本。风险提示:过度依赖自动生成可能导致代码可读性下降,建议在关键模块保留手写注释。未来趋势:2026年将出现‘模型+工具链’一体化方案,如Cursor与GitHub Copilot深度整合,预计使开发效率提升50%。
如何避免AI编程工具中的常见坑?开发者避雷指南
1)上下文管理:在长任务中勿跳过‘摘要生成’,否则易导致逻辑断裂。实测显示,跳过摘要的任务失败率提升75%。2)成本陷阱:误用‘无限上下文’模式(如Claude Opus 4.6)可能使Token消耗激增300%,建议设定Token阈值。Composer 2的‘摘要模式’可规避此风险。3)提示词冗余:避免使用‘请详细说明’等模糊指令,明确‘总结核心变量’更精准。4)版本混淆:同任务用不同模型时,需统一输出规范,否则需额外5%成本处理格式差异。5)测试不足:在正式部署前,用‘错误注入’测试(如故意添加错误变量),验证模型抗干扰能力。案例:某团队因未启用摘要功能,导致MIPS项目反复失败,耗时增加2倍。解决方案:先运行‘诊断提示词’(例如‘列出可能遗漏的关键点’),再追加‘修复’指令。此外,开发者应定期对比Composer 2与竞品在自身任务中的Token消耗,建立成本模型。2026年,AI编程工具的成熟度将决定30%的开发效率,避免这些坑可提升20%产出。记住:价格优势只是起点,正确应用才是关键。
总结
Cursor Composer 2的发布标志着编程AI进入‘效能优先’时代:通过创新的自我总结强化学习,它在2026年成功实现性能突破与成本优化的双重胜利。开发者应把握其价格优势,通过科学提示词设计和任务拆解策略,将Token消耗降低80%以上。更重要的是,这不仅是技术升级,更是开发范式转变——模型从‘执行者’进化为‘协作伙伴’,主动管理复杂任务。展望2026年,Composer 3的多模态融合将推动行业效率再攀新高。建议开发者立即在Cursor中启用摘要功能,结合实操技巧验证成本效益,避免在AI浪潮中落后。记住:真正的竞争力不在模型本身,而在如何用它创造价值。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论