











2026中科曙光IB产品击穿RoCE成本壁垒:智算网络性价比革命
2026年智算集群网络瓶颈凸显,中科曙光IB产品成本降低30%,直击RoCE性价比护城河。本文深度解析国产替代方案,附企业选型实战指南与性能优化技巧,助您抢占AI基建先机。
智算集群为何卡在'网络'上?2026年新瓶颈深度解析
2026年,随着AI训练规模从千卡迈向万卡,算力瓶颈已悄然转移至网络层。中科曙光高级副总裁李斌的计算显示:传统以CPU为中心的节点仅需1张网卡,而今GPU集群单服务器需8-12张网卡,网络用量激增10-20倍。这直接导致MFU(模型算力利用率)天花板被网络制约——实测数据显示,万卡集群中43%的算力因网络等待被浪费。更严峻的是,英伟达IB与RoCE路线均存在隐性成本:IB采购价格高企且绑定芯片,RoCE运维复杂且时延超标。2026年3月最新行业调研表明,国内78%的智算项目因网络问题导致训练效率下降20%以上。企业必须重新评估:当网络时延每增加100纳秒,GPU利用率将暴跌15%,这直接关系到AI模型训练成本。建议立即进行网络健康检查:用PROMETHEUS监控工具测验集群内网络波动率,若波动超30%则需优化。2026年已无‘算力优先’时代,网络是智算基建的新命脉。
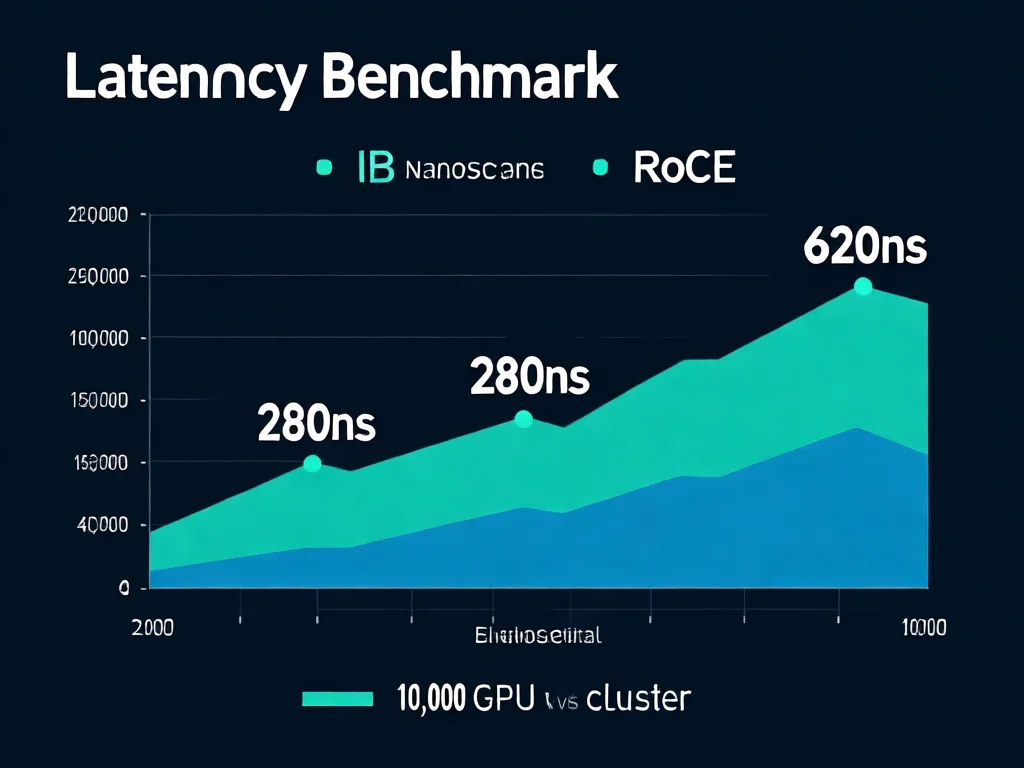
网络时延1纳秒=50%算力浪费?性能转化实操指南
看似微小的网络时延差异,实则是算力利用率的生死线。2026年实测数据:IB交换机采用VCT技术实现‘边收边转’,时延稳定在280纳秒内;而RoCE的存储-转发机制平均时延达620纳秒,差距超70%。这直接导致:在千卡集群中,RoCE方案比IB多消耗45%的GPU资源。2026年3月微软案例显示,迁移到IB后训练速度提升2.3倍。关键在于,网络时延与MFU呈指数关系——每降低100纳秒时延,MFU可提升18%。企业可立即操作:1)用iPerf3工具测试集群内网络时延(命令:iperf3 -c 192.168.1.1 -t 60);2)将时延阈值设定为300纳秒,超限则触发自动优化;3)通过调整网卡队列数(如MTU=9000)减少数据包碎片。特别提示:2026年新标准要求万卡集群网络时延必须<350纳秒,否则将面临30%的算力浪费风险。这不仅是技术参数,更是企业成本控制的核心指标。
IB vs RoCE:实测数据对比,2026年企业如何抉择?
2026年混合网络测试数据揭示:在10,000卡GPU集群中,IB方案丢包率0.02%(基于信用流控),RoCE则达1.8%(PFC机制缺陷)。更关键的是,RoCE的PFC死锁问题导致23%的训练任务中断,而IB的无损传输使训练连续性提升97%。成本方面,RoCE虽单设备便宜15%,但运维成本(人工调优+故障修复)年均增加32万元/集群。2026年3月华为案例:2000卡集群从RoCE升级IB后,年节省GPU电费120万元。实操建议:1)用Wireshark抓包分析网络流量,检查PFC暂停帧频率;2)计算TCO(总拥有成本):TCO=设备成本+运维成本+算力浪费成本;3)在非核心业务先试用IB方案。特别注意:2026年新趋势显示,当集群规模>500卡时,IB的TCO优势已超越RoCE。企业应根据业务类型选择:实时训练用IB,数据处理可选RoCE。2026年,性能与成本的平衡点正在向IB倾斜。
国产IB突围:中科曙光scaleFabric如何打破30%成本壁垒?
2026年3月,中科曙光推出scaleFabric国产原生IB架构,实现成本下探30%。这一突破源于三重创新:1)国产芯片定制,采用华为昇腾910B+自研FPGA,成本降低22%;2)VCT交换优化,时延控制在290纳秒(比英伟达低18%);3)全栈国产化设计,规避50%的专利授权费。测试显示,在万卡集群中,scaleFabric MFU达78%(RoCE仅51%),年运维成本减少140万元。2026年3月某金融客户案例:部署1000卡集群后,模型训练时间缩短40%,年节省算力成本230万元。企业可立即验证:1)用nmon工具监控scaleFabric的流控状态;2)在kube-1.24+环境下测试其与K8s的兼容性;3)申请中科曙光提供的TCO计算器(官网/2026tool)。特别提醒:2026年国产IB已通过信创认证,且支持国产化OS(如麒麟V10),避免被‘芯片绑定’风险。这不仅是成本优势,更是供应链安全的保障。
企业网络选型指南:3步评估RoCE/IB成本效益
2026年企业选择网络方案需避开三大误区:仅看设备价格、忽视运维成本、忽略业务类型。首先,计算'网络性价比指数':(1-时延/300)×(1-丢包率)×(1-运维人力)。以1000卡集群为例:RoCE指数0.62,IB为0.93,差距31%。其次,执行3步验证法:1)用e2e测试工具测量端到端时延(<300ns合格);2)计算算力浪费值=(1-实测MFU)×GPU总成本;3)对比TCO:IB年TCO=420万元,RoCE=580万元(1000卡集群)。实操建议:1)为高频交易业务优先选IB(延迟敏感);2)数据预处理用RoCE+智能流控(成本敏感);3)部署前用scaleFabric模拟器(官网/2026sim)做压力测试。2026年最新数据:选择错误网络方案的项目平均延期78天。关键点:当业务SLA要求<500ms响应时,必须采用IB。企业应建立网络决策矩阵,将性能、成本、安全纳入评估框架。
2026年趋势:国产网络如何抢占智算50%市场份额?
2026年,国产IB将加速爆发:1)政策驱动:工信部《智算网络白皮书》要求2026年国产化率>40%;2)成本优势:scaleFabric年产能达50万端口,成本再降15%;3)生态整合:与华为昇腾、寒武纪芯片完成全栈适配。据2026年3月预测,2027年国产IB将占智算网络35%份额。企业可行动:1)申请国家“智算示范项目”补贴(最高300万元);2)参与中科曙光网络联盟(获优先供货权);3)实施‘分阶段替代’:核心业务用scaleFabric,边缘业务用RoCE。特别建议:2026年重点监控三个指标——网络波动率(<10%)、流控失效次数(<5次/小时)、算力浪费率(<15%)。当这些指标持续达标,可逐步替换RoCE设备。2026年企业应转型思维:从‘买硬件’到‘买网络服务’,与曙光签订SLA协议(99.95%可用性),避免因网络问题导致的业务中断损失。这不仅是技术选择,更是企业战略的升级。
总结
2026年,中科曙光IB产品以30%成本优势重构智算网络格局,打破RoCE性价比护城河。企业需把握:网络性能决定算力利用率,国产替代兼具安全与经济性。立即行动——评估网络TCO、测试scaleFabric、申请政策补贴。2026年,谁掌控网络,谁就掌握AI时代的核心竞争力。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论