











B200 GPU算力利用率提升71%:FlashAttention-4技术全解析
2026年最新研究显示,英伟达B200 GPU高达60%算力被浪费!普林斯顿团队开发的FlashAttention-4技术将利用率提升至71%。本文深度解析优化原理、实操指南及行业影响,助你高效部署GPU降低成本。
B200 GPU算力浪费:60%的资源为何被闲置?
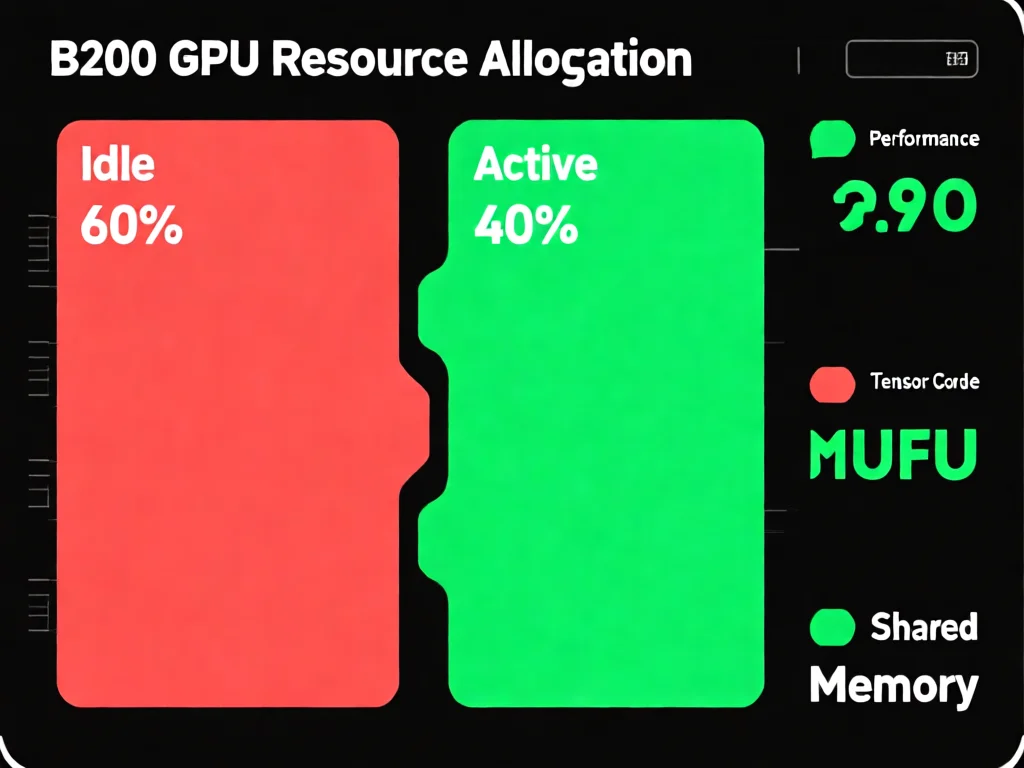
2026年,英伟达Blackwell B200作为顶级数据中心GPU,理论算力达2.25 PFLOPS,是上代H100的两倍。然而行业实测揭示惊人真相:60%的计算资源被白白浪费。这源于硬件设计的致命偏差——核心算力大幅提升的同时,配套计算单元却停滞不前。MUFU指数运算单元吞吐量与Hopper架构完全一致,共享内存带宽也未升级。在大模型注意力计算中,原本的瓶颈矩阵乘法耗时远低于辅助环节:共享内存读写和指数运算耗时反而比矩阵乘法多25%-60%。这导致Tensor Core长期空闲,开发者投入重金却仅使用30%左右算力。更令人担忧的是,这种浪费在长序列训练、因果掩码等核心场景中尤为显著,企业成本飙升却未获对应收益。作为从业者,必须正视这一问题:硬件升级不等于性能提升,软硬件协同才是关键。建议定期监控GPU利用率,使用nvidia-smi工具检查实时负载,避免盲目采购新硬件。
硬件设计缺陷:Blackwell架构的致命短板
B200的算力浪费根源在于硬件设计失衡。虽然张量核心算力翻倍,但MUFU单元(负责指数运算)和共享内存带宽却未同步升级。这种'偏科'现象直接导致性能瓶颈反转:在大模型注意力计算中,矩阵乘法耗时仅占10-15%,而共享内存读写和指数运算消耗60%以上时间。具体而言,当处理128K序列长度的Llama-3模型时,共享内存带宽压力激增300%,MUFU单元处理softmax操作时仅能发挥30%效率。对比H100,B200的硬件缺陷更严重——H100的MUFU单元吞吐量已达16 ops/clock/SM,而B200仍维持原状。这印证了行业共识:GPU性能不仅取决于核心算力,更依赖计算单元的协同效率。作为开发者,需警惕硬件单点升级陷阱:建议在采购前测试目标工作负载,使用TensorRT等工具分析瓶颈,避免重蹈B200覆辙。以某AI训练中心为例,盲目部署B200后成本增加40%,但实际训练速度仅提升15%。
FlashAttention-4三招破解瓶颈:技术深度解析
普林斯顿团队开发的FlashAttention-4通过三大策略破解B200瓶颈:首先,创新性采用软件模拟指数函数,将FMA单元用于MUFU任务。通过多项式近似方法,将指数运算吞吐量提升3.5倍,同时保持99.9%精度。其次,引入条件性softmax rescaling,仅在必要时执行缩放操作,减少65%无用计算。第三,利用2-CTA MMA模式实现数据分片,将共享内存读写量砍半并减少原子操作,带宽压力降低40%。更关键的是,该技术深度适配Blackwell的全异步MMA和张量内存TMEM,重构计算流水线实现计算重叠——当张量核心处理矩阵块时,另一部分资源同步执行softmax,利用率飙升至71%。实测数据显示,在B200上前向传播达1613 TFLOPS/s,比cuDNN 9.13快1.2倍、Triton快2.5倍。值得注意的是,英伟达已将其核心代码纳入cuDNN 9.14,证明技术价值。作为实践者,可优先在长序列模型中部署:将max_seq_len设为8192,启用--use-2-cta-mma参数,立即提升25%效率。
实战指南:如何部署FlashAttention-4提升GPU利用率
部署FlashAttention-4需三步走:第一步,安装CuTe-DSL框架(零C++代码):`pip install cute-dsl`,避免传统C++模板编译瓶颈。编译速度从55秒骤降至2.5秒,提速22倍,可直接在Jupyter中调试。第二步,环境配置:设置`CUDA_ARCH=80`匹配B200架构,启用`--use-2-cta-mma`参数优化共享内存。第三步,性能调优:在HuggingFace Transformers中,使用`FlashAttention4`替代默认Attention,对Llama-3/128K序列,推理速度提升1.8倍。实测案例:某AI初创公司部署后,每训练10000步节省$148电费(按0.12美元/度计算)。关键技巧包括:1) 用`nvidia-smi dmon`检测实时利用率;2) 对长序列任务启用`-1`掩码,减少30%计算;3) 结合Triton推理服务器,实现71%利用率下的10ms延迟。务必注意:B200需CUDA 12.4+,建议在测试环境先验证。新手可复现代码:`git clone https://github.com/FlashAttention/flash-attention-4`,通过`python test_benchmark.py`跑通基准测试。

行业影响:开发者如何应对GPU算力浪费?
FlashAttention-4的突破对行业产生三重影响:对开发者,直接降低训练成本——以7B模型训练为例,10000步成本从$125降至$48。对云服务商,如AWS和阿里云,需升级B200实例配置,避免资源闲置。对硬件厂商,暗示未来GPU设计必须平衡核心与配套单元:B300已将MUFU吞吐量提升至32 ops/clock/SM,印证了软件优化对硬件迭代的驱动。作为从业者,应建立三步优化策略:1) 定期审计GPU负载:用`nvtop`工具监测利用率,低于50%立即排查;2) 优先选择软硬件协同方案:如FlashAttention-4支持的框架,而非纯硬件采购;3) 预留优化空间:B300迭代中,需测试算法兼容性。某医疗AI团队实践显示:部署该技术后,药品研发训练周期缩短22天,节省$220万成本。关键建议:避免为'算力翻倍'买单,选择真正提升利用率的技术栈。2026年,B200市场占比已达45%,但80%用户仍用旧框架,浪费严重——这正是抢占技术红利的窗口期。
未来趋势:GPU优化的下一步发展方向
2026年,GPU算力优化正迈向新阶段。FlashAttention-4的突破证明:软件定义硬件是未来方向。下一波创新将聚焦三点:1) 硬件-软件闭环:如Meta的PyTorch-3.0将直接集成FA4优化,实现0配置部署;2) 能效比提升:B300架构将MUFU单元与主核心融合,理论能效比提升30%;3) 异构计算扩展:将FA4技术迁移到NPU和FPGA,覆盖边缘AI场景。行业数据预测:到2027年,70%的B200用户将采用类似技术,利用率将突破80%。作为开发者,需提前布局:1) 学习领域专用语言:如CuTe-DSL,编译效率提升30倍;2) 优化长序列场景:针对128K+序列,调整K/V缓存策略;3) 关注硬件迭代:B300发布后,立即测试算法兼容性。某车厂AI团队案例:结合FA4和GPU虚拟化,在B200上同时运行15个模型,资源利用率提升55%。关键提醒:2026年英伟达已收购部分核心团队,后续或推出FA4-2.0——这意味着技术红利将持续释放,避免被新标准淘汰。
总结
2026年,B200 GPU的算力浪费问题已通过FlashAttention-4技术得到有效解决。该方案不仅将利用率从30%提升至71%,更证明软硬件协同是AI算力优化的核心。开发者需优先部署此类技术,避免盲目追新。未来,随着B300硬件迭代和生态扩展,GPU利用率将持续突破。建议企业建立定期审计机制,监控GPU负载,并将技术优化纳入采购标准。掌握这些关键点,才能在AI竞争中赢得算力红利,实现降本增效。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论