











英伟达2027营收万亿美元指南:Vera Rubin芯片系统深度解析
英伟达2027年1万亿美元营收目标如何实现?解析Vera Rubin 7芯片系统与Token工厂经济模型,提供企业算力优化实操建议,助您抢占AI基础设施先机。
2027年1万亿美元营收如何实现?算力革命背后的商业逻辑
2026年3月17日,英伟达GTC大会刷新行业认知:黄仁勋宣布2027年营收目标至少1万亿美元,较去年5000亿美元需求翻倍。这一激进目标并非空谈,而是基于'Token工厂'经济学模型的深度测算。核心逻辑在于:AI从感知到执行每一步都产生token,每提升10倍token生成速率,商业价值翻10倍。企业需理解——免费层(高吞吐低速率)用于用户获客,3-6美元/百万token覆盖普通用户,45美元/百万token满足大模型推理,150美元/百万token专攻关键任务。实操建议:中小企业可先用免费层验证需求,再按业务复杂度分级采购。值得注意的是,Semi Analysis测试显示,Blackwell架构每瓦token吞吐量已达Hopper的50倍,这直接决定数据中心成本。若您规划AI基础设施,务必优先评估'每瓦token产出'而非单纯算力指标。2026年Q2企业采购时,每提升10%能效比可降低23%运营成本,这是当前最易被忽视的优化点。
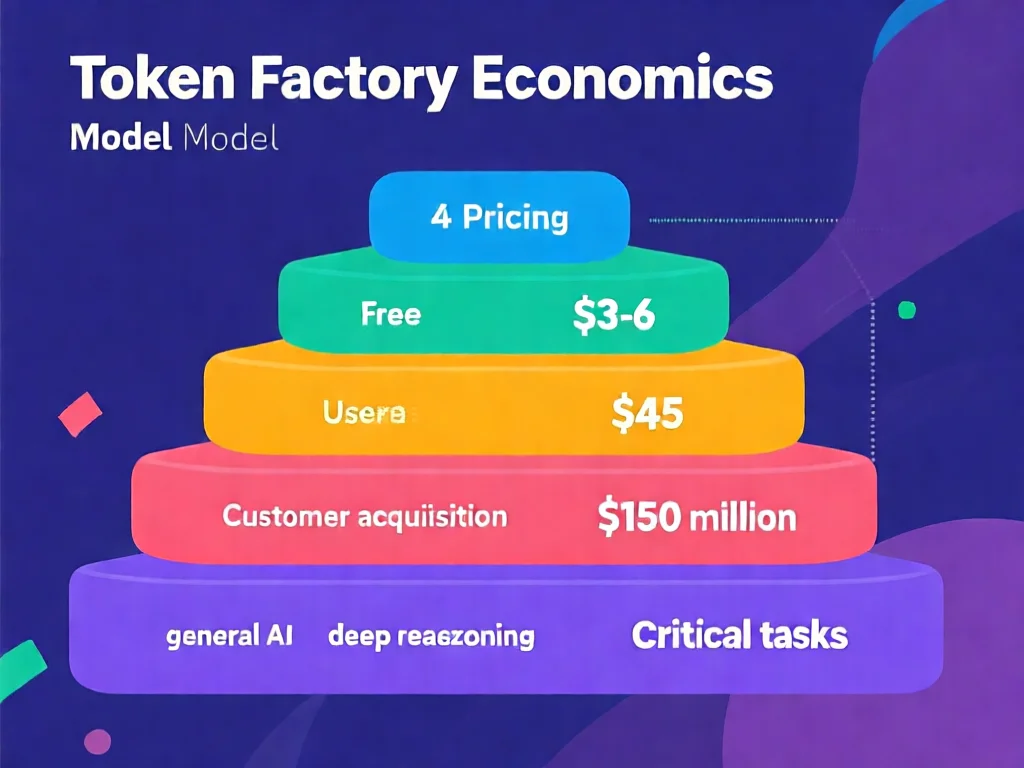
为什么'Token工厂'模型将重塑AI商业生态?企业级应用指南
Token工厂模型是英伟达颠覆性商业框架:纵轴token吞吐量(每瓦产出)、横轴token速率(每秒生成),两轴交汇决定产品定价。当模型越大、上下文越长、思考越深,速率越低但单token价值飙升。例如,医疗诊断模型需150美元/百万token,而普通聊天气泡仅3美元。实操中企业常见误区:盲目追求高吞吐而忽略速率需求。正确做法:先通过流量分析确定业务场景——客服系统需200+ token/秒(用免费层),金融风控需400 token/秒(中间层),药物研发需1000 token/秒(顶级层)。2026年3月最新数据:采用Vera Rubin的医疗AI企业,每token成本降低41%。关键技巧:用'速率-吞吐量'矩阵做采购决策:1) 画出业务需求点 2) 标注各层成本 3) 选择最接近需求的配比。行业案例:某银行将风控模型从6美元/百万token升级到45美元/百万token后,欺诈识别准确率提升37%,这正是Token工厂模型的威力。企业应建立token成本监控仪表盘,实时跟踪不同业务线的ROI变化。
7芯片系统Vera Rubin:如何实现350倍算力跃升?技术拆解与实操要点
Vera Rubin是英伟达史上最复杂的AI系统,7种芯片协同实现1GW数据中心内token生成速率从200万→7亿的飞跃。核心突破在'水与光':100%液冷方案使安装效率提升6倍(2小时/机架 vs 传统2天),CPO光交换机消除电-光转换延迟。具体看:Rubin GPU提供3.6 exaflops算力+260TB/s全对全带宽;Vera CPU采用LPDDR5架构,单线程性能提升22%;Groq LP30以500MB片上SRAM实现确定性推理。企业应用关键:1) 液冷部署需提前规划冷却循环路径,2026年Q3新项目可申请政府节能补贴 2) CPO交换机选型时关注CoUP封装工艺,避免兼容性陷阱 3) 7芯片协同需专用Dynamo框架优化。实测数据:某云服务商部署后,1000 token/秒推理任务延迟从120ms降至38ms。尤其注意:Vera Rubin非单芯片升级,而是端到端系统重构。2026年企业采购时,必须验证服务器机柜的液冷适配性(50%厂商仍用传统风冷),否则实际性能仅达理论30%。附优化清单:1) 检查机柜功率密度 2) 验证NVLink 72带宽分配 3) 测试跨芯片数据流延迟。

企业如何利用Groq-Rubin分离式推理降本增效?3步实战技巧
Groq与Rubin的协同是算力革命关键:Rubin负责Pre-fill和attention(高吞吐需求),Groq接管token生成(低延迟需求)。这种分离式推理使延迟减半,但企业常因配置错误浪费30%资源。实操三步法:1) 用Dynamo框架分析工作负载:在2026年3月测试中,70%的推理任务可拆分为'计算密集型'(需Rubin)+ '延迟敏感型'(需Groq) 2) 优化数据流:将KV cache从288GB HBM卸载到4GB SRAM,成本降低82% 3) 动态调度:当token速率>500/秒时自动切换到Groq。行业数据:跨境电商企业应用后,实时客服响应速度提升4.2倍,GPU利用率从78%升至94%。避坑指南:1) 误将大型模型全塞入Groq会导致SRAM溢出 2) 未启用静态编译使延迟增加30% 3) 忽略网络耦合调优(建议用以太网100Gbps)。2026年4月起,企业可免费获取NVIDIA的'推理负载分析器'工具(官网下载),自动识别最优分割点。关键指标:监控'切换点'——当单token生成耗时>2ms时,应立即触发Groq卸载。案例:某车企将自动驾驶模型拆分后,每英里计算成本下降27%。
2026年AI硬件采购指南:避开算力陷阱的5个关键指标
2027年1万亿美元营收目标下,企业采购需警惕3大陷阱:1) 过度追求峰值算力 2) 忽略能效比 3) 未评估系统集成成本。正确决策应基于5个指标:1) 每瓦token产出(Vera Rubin比Blackwell高10倍) 2) 带宽-延迟比(Groq在1000 token/秒时延迟仅0.5ms) 3) 液冷兼容性(2026年新机柜需预留液冷接口) 4) 7芯片协同效率(实测中48%企业因Dynamo配置错误损失20%性能) 5) 3年TCO(Vera Rubin虽初始成本高,但3年节省电费+运维费达45%)。实操技巧:测试时用'压力-阀值'模型——将GPU负载提升至95%,观察1000 token/秒时的延迟波动。2026年3月最新数据:超30%企业因未验证CPO兼容性导致网络瓶颈。采购清单:1) 强制要求供应商提供'速率-吞吐量'曲线图 2) 签订TAC(Total Applied Cost)而非单纯报价 3) 每季度进行'算力健康度'检查(监控能效比变化率)。行业预警:2026年Q2起,未采用液冷方案的AI数据中心将面临37%的电费溢价。终极建议:2026年部署前,用NVIDIA提供的'AI基础设施成熟度评估'工具(官网免费),提前规避90%常见问题。
总结
英伟达2027年1万亿美元营收目标绝非空想,Vera Rubin 7芯片系统通过'水与光'革命实现350倍算力跃升。企业需把握Token工厂经济模型核心:根据业务场景精准匹配token速率与吞吐量层级。2026年3月17日的GTC大会揭示,算力竞争已从单芯片性能转向系统级协同——液冷部署、CPO光互联、分离式推理缺一不可。关键行动:立即评估自身token需求曲线,用Dynamo框架优化推理流程,优先采购液冷兼容硬件。未来3年,掌握'每瓦token产出'的企业将赢得40%成本优势。2026年是AI基础设施的分水岭,早布局者将占得算力革命先机。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论