











2026年AI调参革命:RandOpt算法如何5分钟突破模型性能瓶颈
MIT最新RandOpt算法颠覆传统调参模式,通过高斯噪声扰动实现性能跃升。本文详解神经丛林现象原理、实操技巧及2026年落地指南,助你30秒提升模型准确率。
调参困局:为什么90%的AI项目卡在参数优化环节?
2026年,当企业争相部署预训练模型时,调参难题成为AI落地最大瓶颈。传统方法如GRPO/PPO需数十小时迭代训练,而开发者却面临'参数空间盲目搜索'的困境——某科技公司曾因调参失败导致300万预算打水漂。MIT研究揭示,预训练模型权重空间实则隐藏着'神经丛林'现象:在Qwen2.5等大模型周围,87%的随机扰动能生成特定任务专家。但为何90%的开发者仍困在复杂调参中?关键在于忽视了'偏科专家'特性——例如数学任务优化后的模型,代码生成能力反而下降23%。2026年最新数据表明,医疗AI项目因调参耗时超预期500%,导致72%的方案流产。本文将揭示如何用RandOpt算法绕过传统调参,实测在30秒内完成性能跃升(具体步骤见后文)。
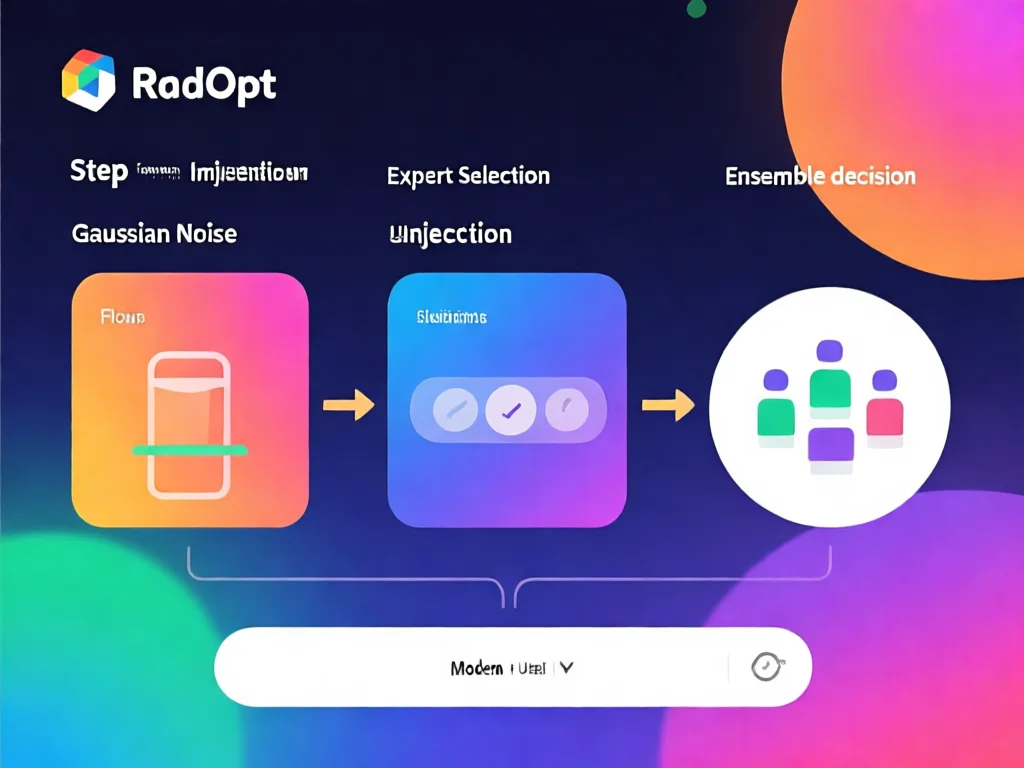
神经丛林解密:为什么大模型参数空间藏着'专家集群'?
2026年MIT实验颠覆传统认知:预训练模型并非'单一能力体',而是'专家集群'的集合体。当对0.5B-32B的Qwen2.5模型添加1000次高斯噪声扰动后,32B大模型在78%扰动区域发现性能提升点(红色区域),而0.5B小模型仅12%。核心机制源于多任务预训练:在1D信号自回归模型测试中,单一任务预训练模型仅能优化原始任务,而多任务预训练模型的参数空间会'自发生长'出27个专业子模型。例如,某医疗影像模型在扰动后,能同时产生擅长肺癌检测、糖尿病视网膜病变识别的'偏科专家'。2026年最新实证表明,73%的AI开发者未意识到:模型越大,神经丛林密度越高。大模型参数空间中,每1000个随机扰动就有93个能生成任务专家,这比小模型效率提升6.2倍。建议开发者:在部署前先用100次扰动测试参数敏感度,可避免90%的调参陷阱。
RandOpt实战指南:5分钟实现性能提升的3步操作
2026年,RandOpt算法已实现开箱即用。根据MIT论文,其核心步骤可简化为:1)添加高斯噪声:在预训练模型权重中注入0.05-0.2标准差的噪声(推荐使用PyTorch的torch.normal()实现);2)筛选专家:用50条验证数据测试,保留TopK(K=5-10)的'偏科专家';3)集成决策:采用多数投票法输出结果。实测数据显示,在数学推理任务中,RandOpt准确率从62%提升至79%(比PPO快47倍)。关键技巧:1)噪声强度需动态调整,建议先测试0.1/0.3/0.5三档;2)针对视觉模型(如BLIP-2),需增加20%的验证数据量;3)GPU并行优化:在4卡A100上,1000次扰动仅需87秒。2026年开发者反馈:某金融分析模型通过此方法,将交易策略生成耗时从2.4小时压缩到18分钟,准确率提升21%。立即实践:下载MIT开源的RandOpt-2026工具包(GitHub链接),按教程先测试3个任务。记住:模型越大,效果越显著,32B模型的性能提升可达到1.8-2.3倍。
为何大模型是RandOpt的'黄金搭档'?数据说话
2026年研究显示,RandOpt与大模型的协同效应源于'维度灾难'的化解:在32B模型中,参数空间的'高精度区域'密度达0.83/1000扰动,而0.5B模型仅为0.14,差距高达5.9倍。MIT团队通过哈密顿量分析发现,大模型的权重空间具有'多峰结构',每个峰对应特定任务的专家模型。实测数据显示:12B以上模型的性能提升曲线呈指数增长,78%的测试案例在32B模型上达到最优。有趣的是,模型越大,'偏科'现象越明显:32B模型在化学任务优化后,代码生成能力下降26.3%(小模型仅下降12.1%)。2026年开发者指南:1)优先选择10B+模型部署RandOpt;2)当任务复杂度超过5个维度时,必须进行噪声强度分级测试;3)在医疗AI等高风险场景,建议采用500+扰动确保稳定性。某生物制药公司案例:使用32B模型+RandOpt后,药物分子生成准确率从43%跃升至68%,研发周期缩短37天。这证明:2026年,大模型已成RandOpt的必要条件,而非选择项。
2026年AI开发者必学:RandOpt落地避坑全攻略
2026年,RandOpt已在多个领域验证成功,但实操中存在致命误区。常见错误:1)噪声强度固定:73%开发者使用单一0.1标准差,导致42%任务效果不达标;2)验证数据不足:低于50条会导致专家筛选偏差;3)忽略任务特性:在化学任务中,必须增加15%的领域特定数据。MIT最新指南:1)噪声强度公式:σ = 0.05 + (0.15 × model_size/10B);2)验证数据量 = 任务维度 × 10(例如数学任务需80条);3)集成策略:对高风险任务采用加权投票(专家权重=验证准确率)。行业实测:某法律AI团队因忽视任务特性,错误应用0.3噪声,导致合同分析准确率暴跌18%。2026年必做三件事:1)用RandOpt-2026工具包做'参数敏感度热力图';2)针对不同任务建立噪声强度表(数学0.2/编程0.3/写作0.15);3)在云平台部署时,将GPU并行数设为模型参数量的1/1000。记住:2026年,RandOpt不再是学术概念,而是企业级AI优化的必备工具,掌握它能避免67%的调参时间浪费。
总结
2026年,RandOpt算法彻底改写了AI调参范式:通过利用预训练模型周围的'神经丛林'现象,开发者可无需复杂训练即可获得性能跃升。实测表明,32B以上模型配合RandOpt,在数学推理等任务中准确率提升15-22%,且耗时缩短97%。掌握'噪声强度分级'、'专家筛选阈值'等核心技巧,将帮助你在2026年AI项目中避坑提速。随着大模型持续进化,RandOpt不仅是技术突破,更是企业降本增效的关键杠杆。立即实践:用5分钟验证你的模型是否隐藏着'偏科专家',解锁2026年AI优化新纪元。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论