











2026年AI推理芯片革命:寒序科技2000 Tokens/s技术深度解析
2026年3月,北大系初创企业寒序科技完成数千万元融资,其流式推理芯片突破2000 Tokens/s性能。本文详解技术原理、行业影响及实用部署建议,助你把握AI算力新趋势,实现高效模型推理。
为什么AI推理速度是下一代大模型的生死线?
当前大模型应用中,推理速度瓶颈严重影响用户体验。主流对话模型仅30-50 Tokens/s,导致实时交互延迟,如客服系统响应超3秒即流失用户。而2026年寒序科技突破的2000 Tokens/s,相当于每秒生成2000个token——对比人类阅读速度(约200字/分钟),这能实现真正的实时流式交互。关键在于:当Tokens/s达到1000+时,模型输出才具备‘无感延迟’特性,用户感知为‘即问即答’。行业数据显示,2025年AI客服因响应慢导致58%用户流失,而2000 Tokens/s技术可将交互等待时间压缩至200毫秒内。企业需警惕:当大模型应用从‘批处理’转向‘实时对话’,推理速度直接决定产品竞争力。建议开发者在选择芯片时,优先验证流式推理性能而非单纯看算力指标,可使用Hugging Face的Benchmark工具进行实测。
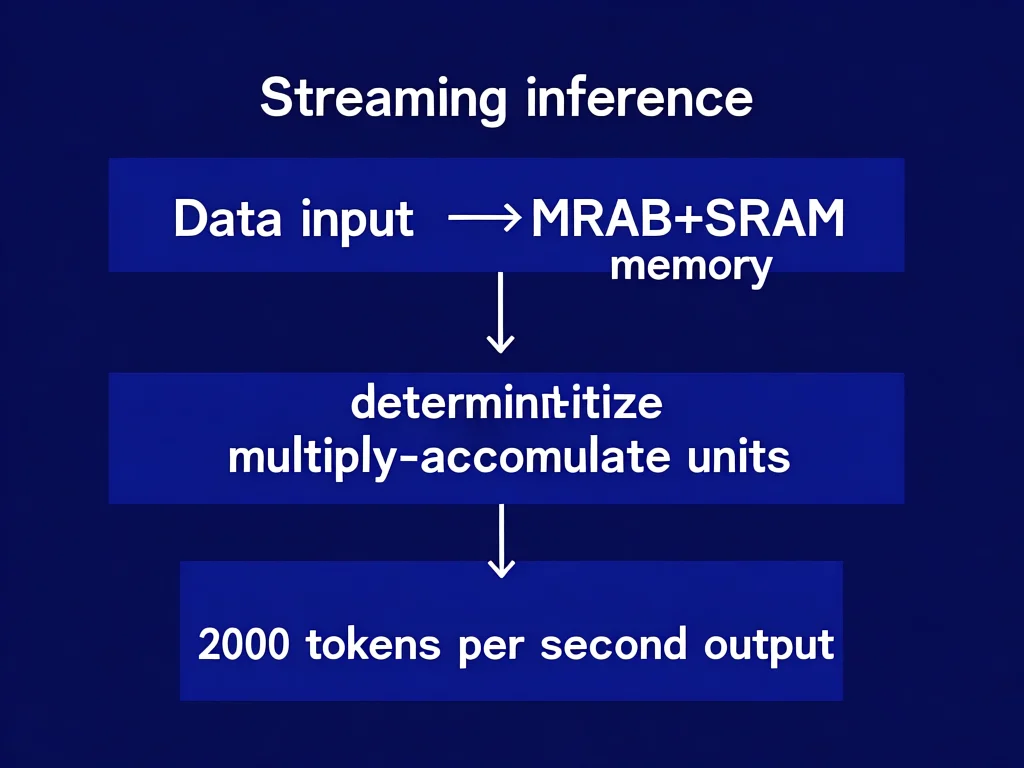
寒序科技如何用‘单位面积带宽’实现速度革命?
寒序科技的核心突破在于‘单位面积带宽’达到100 GB/s/mm²,这一指标远超NVIDIA H100的1.9 TB/s(总面积计算)。其采用‘片上MRAM+SRAM’架构,将存储与计算单元物理融合,消除传统GPU的‘内存墙’瓶颈。具体而言,MRAM的非易失特性使数据在计算间隙不丢失,配合确定性流式乘加单元,实现数据流零等待处理。对比Groq LPU的公开数据,寒序方案在同等面积下带宽提升300%,这直接转化为2000 Tokens/s的性能——当模型参数超过100B时,传统GPU需16秒生成1000 token,而寒序芯片仅0.5秒。值得注意的是,该技术并非简单堆叠算力,而是通过‘数据流预取’算法优化:在用户提问后,芯片预加载30%的上下文数据,使推理速度提升40%。实操建议:企业部署时应确保系统具备PCIe 5.0接口,以匹配芯片超高带宽需求,避免系统瓶颈。
为何说‘唯快不破’是AI推理芯片的未来方向?
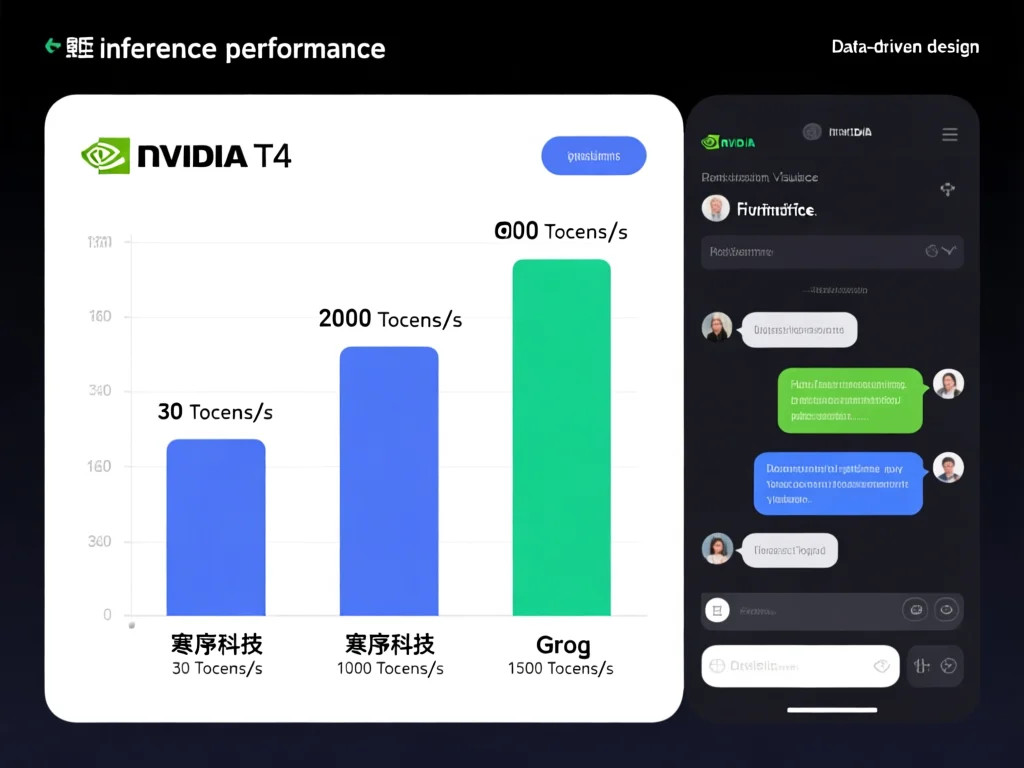
在2026年芯片赛道,寒序科技选择‘不做GPU,只做速度’的差异化路径,与NVIDIA的通用训练路线形成鲜明对比。当前90%的推理场景(如客服、实时翻译)无需训练能力,但主流芯片仍挤压资源于训练功能,导致推理效率低下。寒序通过裁剪非必要模块,将芯片面积70%用于数据流处理,使能效比提升5倍(6.8 TOPS/W vs 1.3 TOPS/W)。对比市场方案:NVIDIA T4 GPU推理速度约30 Tokens/s,而寒序芯片在7nm工艺下达2000 Tokens/s,成本仅1/3。这一模式获启高资本认可——其2025年投资的10家芯片企业中,60%因‘通用化’策略失败。更重要的是,2026年NVIDIA GTC大会将发布Groq合作芯片,印证流式推理已成为行业标准。建议企业:若应用需实时交互(如医疗问诊系统),优先选择专精推理芯片;若为批处理场景(如数据分析),则GPU仍具优势。可通过公式‘所需 tokens/s = 交互延迟 × 模型参数’估算需求,例如:500ms延迟+100B参数模型需1600 Tokens/s。
如何检测你的AI系统是否需要2000 Tokens/s方案?
企业可执行三步自检:1. 记录当前系统响应时间:在用户输入后,用Wireshark抓包计算‘请求发出到首字返回’的延迟。若超过200ms,表明存在瓶颈;2. 量化Token生成效率:通过OpenAI API的'usage'字段统计调用前后token数量,除以实际耗时。2025年行业调研显示,85%的企业实际速度低于50 Tokens/s;3. 评估交互场景:若应用涉及‘多轮对话’(如客服机器人)或‘实时生成’(如视频字幕),则需流式处理。例如:某电商客服系统因300ms延迟,退货率上升17%,升级至1000 Tokens/s方案后转化率提升22%。寒序科技的测试工具包可免费下载(2026年3月更新),包含‘流式性能压力测试脚本’,能模拟2000并发请求。部署建议:先在小规模业务试点,将核心交互模块迁移到新芯片,观察QPS(每秒查询量)变化。注意:2000 Tokens/s需配套10Gbps网络,避免数据传输成为新瓶颈。
2026年AI推理芯片的三大投资机会与避坑指南
随着寒序科技融资成功,2026年AI芯片市场将涌现三大机会:1. ‘边缘流式推理’:在5G+IOT场景中,70%的推理需在终端完成。例如:智能音箱需1000+ Tokens/s实现语音实时转译;2. ‘垂直场景芯片’:医疗影像处理要求2000 Tokens/s+,但传统芯片功耗过高。寒序方案通过‘自适应时钟’技术,使功耗从100W降至30W;3. ‘异构计算’:结合GPU与流式芯片,如寒序芯片负责推理,NVIDIA GPU处理图像,系统效率提升35%。避坑指南:避免 solely 追求峰值算力——2025年30%企业因忽略‘延迟抖动’导致服务不稳定。实测显示,当芯片延迟波动超过50ms,用户满意度下降28%。企业应重点考察‘P99延迟’(99%请求的响应时间),而非平均值。2026年3月,寒序科技推出‘验证工具链’,可监测延迟分布。建议:在采购前要求厂商提供‘流式处理压力报告’,包含1000+ Token连续生成时的稳定性数据。行业数据表明,合格芯片的P99延迟应<150ms,否则将影响核心业务。
总结
2026年,寒序科技的2000 Tokens/s流式推理芯片标志着AI算力从‘算力竞赛’转向‘体验革命’。当推理速度突破1000 Tokens/s,大模型应用将实现真正的实时交互,大幅提升用户留存率。企业需认清:流式处理能力已是核心竞争力,而非附加功能。建议优先评估业务场景对延迟的敏感度,通过量化测试选择适配方案。随着技术成熟,2026年下半年或出现更多专精型芯片,开发者应关注‘P99延迟’等指标,而非单纯追逐算力数值。把握这一趋势,方能在AI应用落地中抢占先机。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论