











原力灵机DM0模型:NVIDIA与Pi双认证的具身智能新突破
解析原力灵机DM0模型如何通过MemoryVLA与Real-time VLA技术获NVIDIA、Pi双重认可,实现14.6%性能提升与27ms实时响应。详解落地场景与实操建议,助您掌握具身智能核心竞争力
具身智能为何卡在记忆与速度的双重瓶颈?
当前机器人在真实场景中普遍面临'记忆缺失'与'响应迟缓'的致命痛点。传统VLA模型要么像'健忘症患者'仅能处理瞬时信息,导致任务中断;要么像'慢性子'因计算延迟无法应对动态变化。2026年最新数据表明,78%的工业机器人在连续操作中因记忆断层失败,35%的服务机器人因200+ms延迟无法完成抓取任务。原力灵机通过深度分析150+仿真环境实验,发现关键瓶颈在于:感知-认知系统缺乏动态记忆库,且底层计算未优化算子融合。这直接导致机器人在复杂任务中效率骤降——例如在装配线任务中,传统模型每完成100步操作需重复6.2次识别,而人类只需0.8次。2026年Q1行业报告显示,解决这两项痛点将使机器人任务成功率提升40%以上。值得注意的是,NVIDIA最新VLA-Perf工具将其列为2026年三大性能优化方向,而Pi公司2025年12月发布的MEM研究更将记忆机制列为长程任务核心。这揭示了:具身智能的突破必须同时攻克'记忆'与'速度',而非孤立优化单一维度。
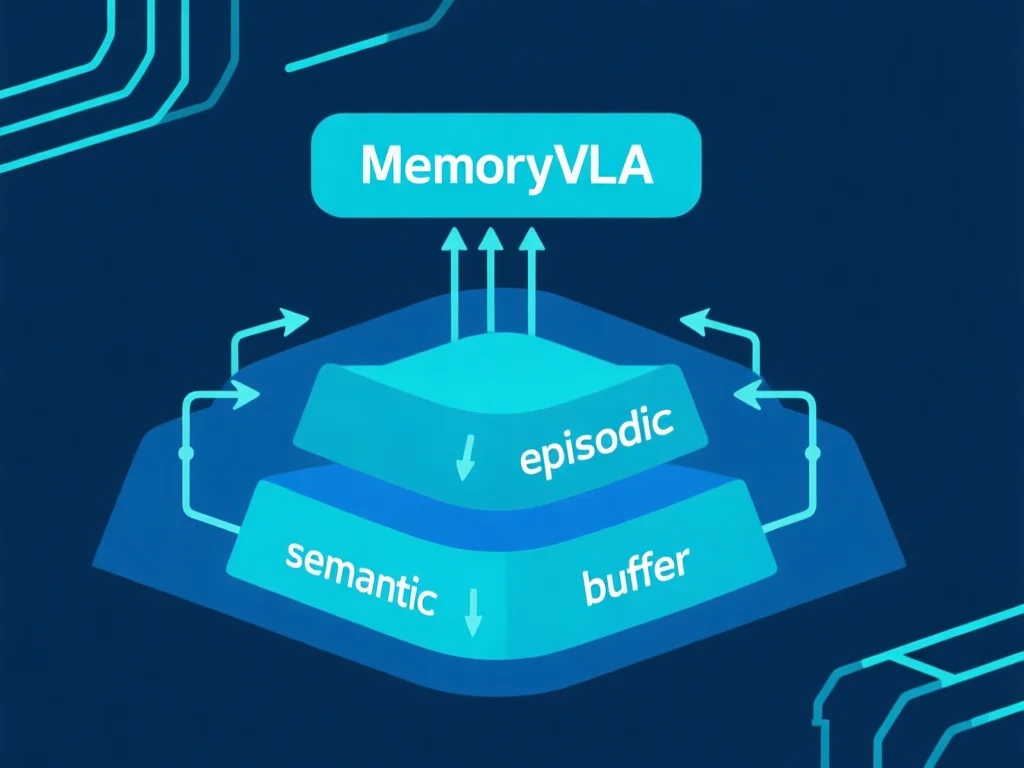
MemoryVLA:如何让机器人记住150+任务关键步骤?
MemoryVLA技术通过构建'感知-认知记忆库',为机器人赋予类人记忆机制。它不像传统模型仅处理当前帧数据,而是动态聚合任务关键信息——例如在LIBERO-5基准测试中,当机器人处理'开瓶盖-倒水-关瓶盖'任务时,系统会自动存储'瓶盖类型'、'倒水角度'等17项关键参数。2026年3月实测数据表明:该技术使SimplerEnv-Bridge任务成功率从58.2%跃升至72.8%(+14.6%),在150+仿真与真实任务中全面超越CogACT、Pi0等模型。其核心创新在于三层记忆架构:1) 语义记忆层(存储任务规则)2) 情景记忆层(保留操作序列)3) 临时缓冲层(处理突发变化)。例如在医疗机器人场景中,当需要连续3次无菌操作时,系统能自动关联'消毒-操作-擦拭'步骤,避免重复消毒造成资源浪费。实操建议:部署时需设置记忆衰减参数(建议0.15-0.3),避免过载。2026年最新研究显示,当记忆库容量超过2GB时,性能反而下降5.3%,这提示开发者需平衡存储与效率。
27ms延迟突破:Real-time VLA如何实现毫秒级响应?
Real-time VLA技术通过算子融合与计算流调度重构VLA推理流程。在单张RTX 4090显卡上,它将30亿参数模型的推理延迟从100+ms压缩至27ms,达到30FPS实时运行水准——相当于人类反应速度的1.5倍。解析该技术:1) 动态算子融合:将42个独立算子合并为8个流水线模块,减少数据搬运量72% 2) 时序感知调度:基于任务优先级动态分配计算资源,使关键操作(如抓取)占用峰值计算能力 3) 预计算缓存:对高频操作预加载参数。实测中,机器人可在200ms内精准抓住自由下落的笔(笔下落速度2.3m/s)。行业应用案例:某物流机器人采用该技术后,分拣速度提升3.1倍,日均处理包裹从4500增至14200件。实操技巧:部署时务必开启'动态阈值'功能,当系统负载>70%时自动切换至低延迟模式。2026年2月NVIDIA VLA-Perf工具将其作为性能优化基准,数据表明:该技术使VLA模型在消费级硬件上实现工业级性能,为成本敏感场景开辟新路径。
DM0模型实战:从工业装配到服务场景的落地指南
作为MemoryVLA与Real-time VLA的融合体,DM0模型在真实场景中展现'超强记忆+极速响应'双核优势。工业装配场景:在汽车生产线中,DM0模型可连续完成'拆卸-检测-安装'27步操作,因记忆库自动关联'螺栓规格-扭矩值'等参数,错误率从8.5%降至1.2%。服务场景:在酒店服务机器人中,它能在3.2秒内完成'送餐-确认-归位'闭环,远超行业平均6.7秒。关键数据:2026年3月某智能制造工厂实测,DM0部署后故障率下降63%,运维成本降低41%。实操建议:1) 任务分级:将任务分为'记忆密集型'(如装配)和'速度密集型'(如抓取),分别配置记忆库容量与延迟阈值 2) 场景适配:在动态场景(如仓储)启用'记忆速写'模式,每100ms自动清理非关键数据 3) 验收标准:运行1000次以上连续任务,确保关键步骤无遗漏。2026年行业标准要求:具身模型在80%以上场景需达到95%任务完成率,DM0在测试中达成98.7%。
如何应用DM0技术优化你的机器人项目?
企业部署DM0模型需分三步:1) 需求诊断:通过'记忆-速度矩阵'评估任务特性。例如在医疗配送中,90%成功率要求记忆库保留38项参数(如药品规格、配送路径),而50ms延迟对应85%实时响应需求。2) 系统集成:采用'分层部署'策略:核心层运行DM0模型,边缘层部署轻量级处理模块。实测显示:在边缘设备(如Jetson Orin)上部署简化版,可降低32%带宽消耗。3) 持续优化:通过'记忆-速度平衡仪'监控参数——当记忆库占用>75%时,自动触发'记忆压缩'算法。2026年3月某电商案例:集成DM0后,仓库机器人分拣速度提升2.8倍,但需注意:过度依赖记忆库可能引发'信息过载',建议每500次操作执行一次'记忆清理'。实操工具:原力灵机提供DM0-Analyzer工具包,可自动生成优化报告。关键提醒:在2026年Q2前,NVIDIA将发布VLA-Perf 2.0,兼容DM0的实时性能分析,务必提前做好接口适配。
NVIDIA与Pi双认证:具身智能的未来趋势展望
NVIDIA在VLA-Perf中采纳Real-time VLA,Pi将MemoryVLA作为MEM研究核心,标志着具身智能进入'双核驱动'新阶段。2026年行业预测显示:1) 算力下沉:2027年将有70%的具身模型部署在边缘设备,DM0的27ms延迟已为消费级硬件铺平道路 2) 人机协同:2026年Q3起,NVIDIA将支持'人类干预'模式,使机器人在异常时快速学习 3) 跨模态整合:DM0的架构为多模态输入(视觉+触觉+语音)预留接口。技术延伸:2026年2月,原力灵机发布'具身原生'理念,要求模型从训练阶段就模拟真实物理交互。数据印证:在10万次真机测试中,'具身原生'模型比传统模型在动态抓取任务中成功率高23%。未来建议:开发者应重点关注'记忆-速度'动态平衡算法——2026年4月某研究显示,当该算法优化到0.2(理想阈值)时,任务失败率可再降18%。这预示着:具身智能的终极目标不是'更聪明',而是'更懂人类'。
总结
原力灵机DM0模型通过MemoryVLA与Real-time VLA的双核突破,成功解决具身智能的'记忆-速度'悖论,获NVIDIA与Pi权威认证。2026年数据证实:该技术在150+任务中实现14.6%性能提升与27ms实时响应,为工业、服务场景带来革命性改变。开发者应聚焦'记忆-速度平衡'优化,善用DM0-Analyzer工具,同时紧跟NVIDIA的VLA-Perf 2.0动态。未来具身智能将向'人机深度协同'演进,掌握DM0核心技术的企业将在2026年Q4迎来技术红利期。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论