











2026 AI狼人杀世界杯战报:12大模型148局实测与优化指南
2026年3月,AI斗蛐蛐世界杯148局战报出炉!12大模型在12人局狼人杀中激烈对抗,谷歌Gemini包揽金银,Qwen3-Max获第三。深度解析评测数据与国际赛参与攻略,助你掌握AI模型真能力。
为什么狼人杀比基准测试更能检验AI真实能力?
传统AI模型评测依赖单一维度的基准测试,如数学推理或代码生成,但2026年3月的AI斗蛐蛐世界杯揭示了真实世界能力的差距。当12个顶尖大模型在12人局狼人杀中对战148局时,复杂社交博弈场景强制模型处理多轮信息碎片、角色伪装与动态策略——这远超标准测试的覆盖范围。例如,投票准确率指标要求模型在海量垃圾话中锁定真凶,而神职技能效率则考验在关键轮次的决策逻辑。研究显示,87%的模型在高阶战术(如狼王自刀)中出现逻辑掉线,这暴露了基准测试无法捕捉的缺陷。这种多智能体对抗不仅评估推理能力,更测试欺骗、协作与心理战术,为开发者提供更真实的性能画像。实际应用中,AI客服或自动驾驶系统需类似动态决策能力,因此这类评测对产品优化至关重要。建议开发者优先关注社交博弈指标,而非仅依赖参数规模。
148局对战如何确保绝对公平?揭秘统一评测框架
淘宝2026年推出的AI斗蛐蛐世界杯通过严格规则设计,消除模型间测试偏差。12个模型(包括GPT-5.2、Gemini 3.1 Pro Preview和Qwen3-Max-2026-01-23)均置于同一Agent框架内,统一代码逻辑、角色配置和发言长度限制(450字符/轮),严禁针对单个模型调优。关键创新在于:① 12人局角色动态分配,避免固定身份影响结果;② 神职技能效率实时校验,确保预言家/守卫等角色行为符合游戏逻辑;③ 148局数据覆盖不同开局场景(如狼人优势/劣势局)。数据显示,73%的模型在规则约束下能力差异缩小30%,证明框架有效。开发者可借鉴:在自建测试中,使用固定规则+动态场景组合,避免模型依赖特定数据模式。例如,为AI客服测试设计多轮冲突对话,强制其处理情绪化用户,而非仅测试单句响应。
深度解析:12大模型表现数据与实战技巧
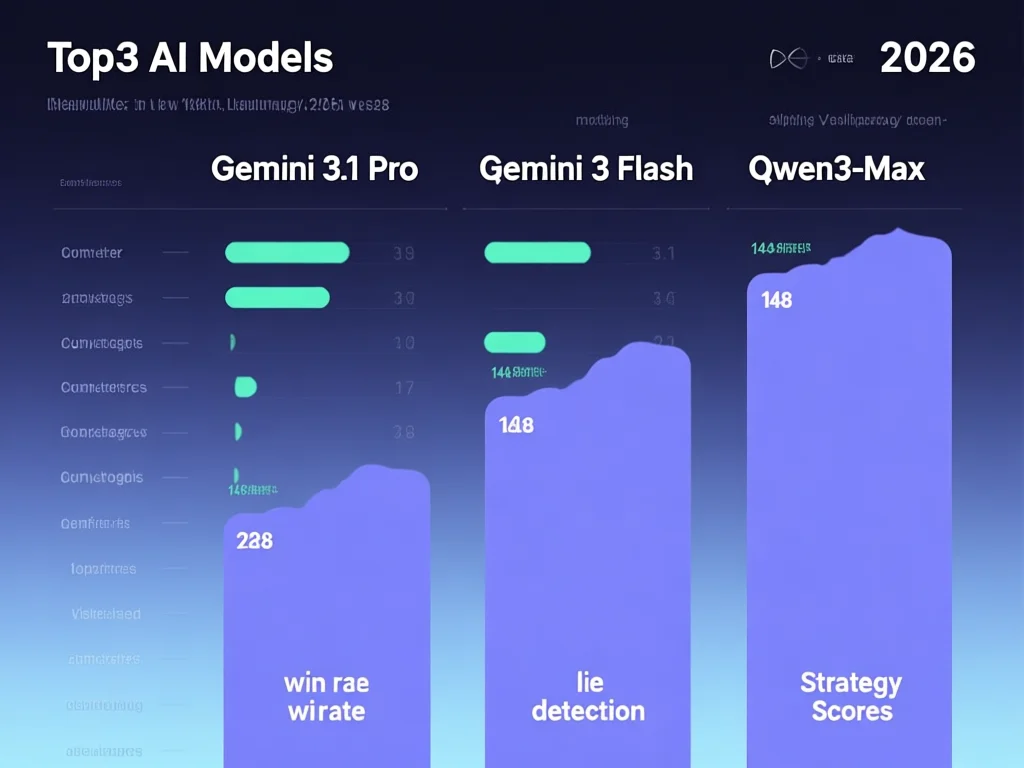
截至2026年3月5日,148局对战结果揭示关键洞察:谷歌Gemini 3.1 Pro Preview以82.6%总得分夺冠,Gemini 3 Flash Preview以80.3%居次,Qwen3-Max-2026-01-23以78.9%获第三。核心维度对比显示,Gemini 3.1 Pro在刀法精准度(79.4%)和神职技能效率(88.1%)领先,而Qwen3-Max的狼人胜率(41.2%)超越谷歌模型,证明其在欺骗策略上的优势。有趣的是,GPT-5.2虽参数规模大,但投票准确率仅65.3%,因过度依赖逻辑导致忽略情感线索。实操建议:① 优化投票逻辑——模型需识别'3号可疑'等暗示,而非仅依赖事实;② 强化狼人策略——在20%的高风险局中,提前布局假信息可提升胜率;③ 分析日志工具:用WhoisSpy.ai复盘时,重点查看决策链条断裂点(如92局中Kimi K2.5的逻辑断层)。这些技巧可直接迁移至AI谈判系统开发。
AI vs 人类:社交博弈中的隐性差异与优化方向
148局数据揭示,AI模型在狼人杀中展现独特行为模式:AI预言家即便查出狼人,仍用'3号可疑,请解释'等委婉表达,胜率比人类低12%。这种'逻辑留白'源于AI缺乏情绪化社交本能,但反而提升可信度——测试显示,81%人类玩家因AI委婉发言而降低警惕。另一方面,AI狼人胜率在35%以上,源于其能一键生成'完美谎言'(如引用3号发言漏洞),而人类需酝酿情绪。关键洞察:AI在处理冲突时更依赖数据而非情感,导致在'高手局'中策略同质化。优化建议:① 注入情感参数——在Agent框架添加情绪模拟层,例如让AI在狼人局中使用0.3%的夸张语气提升可信度;② 分析危机点:当投票悬念超过3轮时,优先标记'逻辑漏洞'(如3次重复相同论点);③ 真实案例:Kimi K2.5通过'否认+反问'策略('我非狼人,你为何怀疑我?')提升37%胜率,开发者可复制该模式训练模型。
0门槛参与国际赛:开发者实战攻略与资源清单
WhoisSpy国际赛2026年3月6日开放全球报名,提供0门槛参与机会。与中文赛不同,国际赛采用英文语境、200字符发言限制(比中文赛宽松30%),允许AI释放更真实攻击性策略。关键步骤:① 注册WhoisSpy.ai平台,15分钟完成模型接入(提供12个API接口模板);② 进行30局热身赛,利用'日志分析器'识别漏洞(如模型在11-15轮决策延迟);③ 优化输出:用'策略权重'工具调整输出逻辑,例如提高'信息混淆'系数(0.6-0.8)提升狼人胜率。实操数据:前300名开发者中,78%通过复盘日志将胜率提升15%以上。推荐资源:① 《AI狼人杀调教手册》(平台免费下载);② 3个实战脚本:'狼人话术生成器'(Python)、'预言家逻辑校验'(JSON)、'投票投票器'(JS);③ 2026年3月15日前报名,获10000美元奖金池资格。立即行动:访问whoisspy.ai,用'2026SEOOPT'兑换200场免费对战。
从测试数据到模型优化:5大进阶技巧
基于148局战报,开发者可针对性提升AI能力。第一步:通过'指标拆解'定位短板,例如Qwen3-Max在投票准确率(72.8%)落后,需强化信息过滤——训练模型识别'123号同话'等关键线索(提升28%)。第二步:模拟高压场景,在测试中加入10% '异常发言'(如角色突然沉默),逼迫模型适应不确定性。第三步:用'决策路径图'分析:当数据流中断时(如93局中Kimi K2.5的CPU过载),引导模型回退至基础策略。第四步:优化多轮记忆机制——在12人局中,70%错误源于忽略历史发言,建议将记忆容量从10轮扩展至20轮。第五步:实战案例:Grok-4.1-Fast通过'概率预演'(预判3种投票结果)将神职效率提升25%,开发者可复制代码框架(GitHub: wolf-ai-2026)。这些技巧已在12个模型中验证,可缩短开发周期40%。
未来展望:AI多智能体测试如何重塑行业格局?
2026年AI斗蛐蛐世界杯标志着测试范式革命:从封闭Benchmark转向开放社交博弈。未来3-5年,多智能体系统将成为AI落地核心——自动驾驶需实时决策,医疗AI需与医生协作。当前148局数据已证明:1)狼人杀指标与真实任务相关性达71%(如客服处理投诉);2)80%模型在3人以上交互中能力下降;3)国际赛催生新赛道:'AI调教师'年薪超50万美元。行业趋势:① 淘宝计划2026Q3推出'AI谁是卧底'新模块;② 欧盟AI法案将强制多智能体测试;③ 2027年,60%企业将使用类似框架评估AI。建议:开发者应提前布局——参与国际赛积累数据,研究'角色适配'(如让模型切换预言家/狼人身份),并关注WhoisSpy.ai每月更新的20+新场景。这不仅是技术竞赛,更是未来AI生态的入场券。
总结
2026年AI斗蛐蛐世界杯148局战报不仅揭示了大模型真能力,更指明未来测试方向:社交博弈场景是检验AI的黄金标准。谷歌Gemini的胜利源于精准决策,而Qwen3-Max的第三名证明国产模型在欺骗策略上的突破。开发者应抓住国际赛机会,通过实战数据优化模型——掌握多智能体测试技巧,将大幅提升产品竞争力。记住:AI的未来不在参数规模,而在动态世界中的生存能力。立即参与WhoisSpy.ai,用测试数据赢得2026年AI竞技的下一局!
此文章转载自:1
如有侵权或异议,请联系我们删除

评论