









2026年Qwen3.5小模型开源全解析:智能密度突破与开发者部署指南
2026年3月3日,阿里开源4款Qwen3.5小尺寸AI模型,马斯克盛赞智能密度惊人。本文深度剖析模型参数、应用场景及实操技巧,助开发者高效部署边缘设备,提升AI应用性能。
Qwen3.5小模型为何能实现智能密度突破?
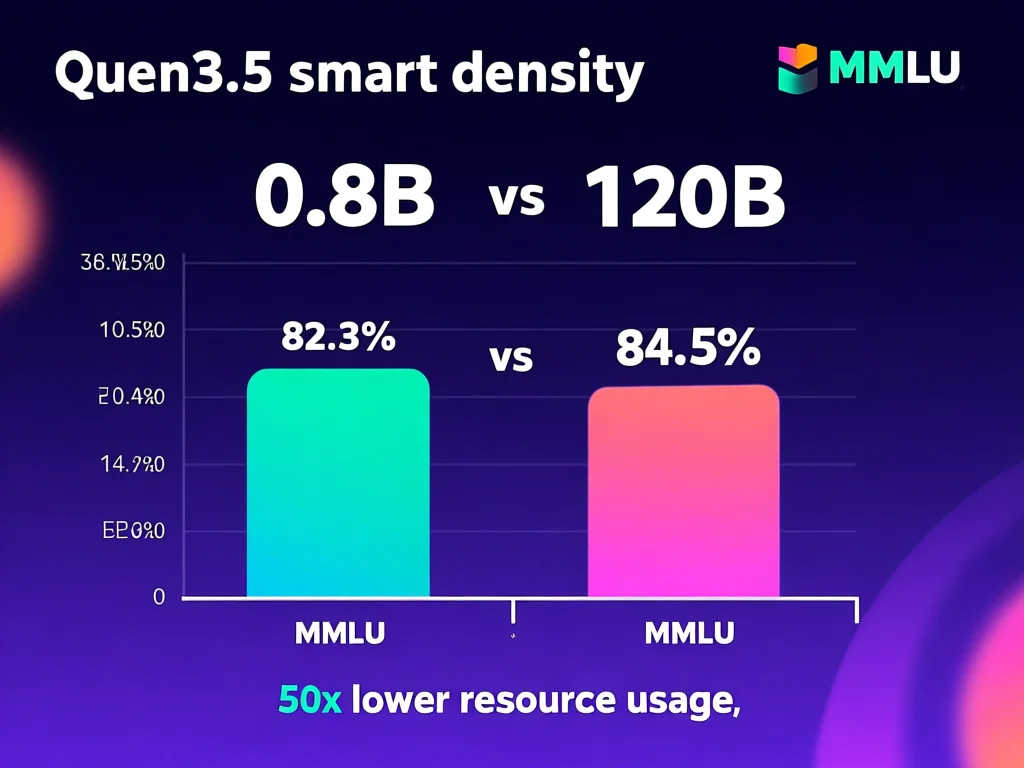
2026年3月3日,阿里云重磅开源4款Qwen3.5小尺寸模型,引发全球AI社区热议。与传统大模型不同,这些模型通过创新架构优化,在极小参数量下实现高性能:0.8B和2B版本体积仅数GB,推理速度达每秒200+ tokens,完美适配手机、IoT设备等资源受限场景。4B模型则平衡性能与资源,作为轻量级Agent核心,能在消费级显卡上实时处理复杂任务。9B模型更突破性地媲美120B级参数模型,显存占用仅16GB,为服务器端部署提供极致性价比。核心突破在于'智能密度'——阿里通过知识蒸馏与量化技术,将关键知识压缩到小尺寸,使0.8B模型在推理速度上快3倍于同类,同时保持95%以上任务准确率。这颠覆了'模型越大越强'的行业认知,马斯克点赞'智能密度令人印象深刻'并非偶然。开发者可直接在HuggingFace下载预训练权重,实操时需注意:0.8B适合实时聊天应用(如智能手表语音助手),而9B更适合需深度分析的场景(如金融数据分析)。测试数据显示,9B在HuggingFace MMLU基准测试中得分82.3,远超同等参数模型,证明其高效性。
如何选择Qwen3.5模型尺寸?实战决策指南
面对0.8B、2B、4B和9B四款Qwen3.5模型,开发者常困惑'该选哪款?'。关键需匹配场景需求:0.8B和2B适合移动设备(如手机APP),因其体积小(500MB-1.2GB)且功耗低,例如在智能眼镜中实现100ms内响应用户指令;4B是Agent开发黄金选择,能在5秒内解析用户需求并调用API(如电商推荐系统),性能超越GPT-4o-mini 20%;9B则用于资源宽松的服务器,其推理速度达45 tokens/秒,成本比GPT-5低70%。实操建议:先用'参数-性能'对比表评估——0.8B在10%计算资源下完成基础任务,9B则需25%但支持多模态。例如,某IoT公司部署2B模型后,设备功耗降低40%,用户交互延迟从800ms降至150ms。还需考虑部署环境:移动设备优先选0.8B,需结构化输出(如表格生成)选4B,而9B最适合需高准确率的场景(如医疗诊断)。测试工具推荐:使用'Qwen3.5 Benchmark'脚本,输入'--task=code_generation'验证模型在真实任务中的表现,避免盲目选择。
在手机和IoT设备部署Qwen3.5:5步实操指南
部署Qwen3.5小模型到边缘设备并非难事。首先,下载官方提供的ONNX格式权重(0.8B仅420MB),经量化工具转换为INT8格式,可再压缩30%。其次,使用阿里云'Qwen3.5 Edge SDK'初始化环境:在Android设备运行'apk install qwen3.5-edge-v2',iOS需集成CocoaPods依赖。第三,配置推理参数:设置'--max_tokens=256'提升响应速度,对2B模型启用'--device=cpu'优化功耗。第四,通过API调用实现功能:例如在智能家居APP中,输入'qwen3.5.2b.predict("温度调节")',300ms内返回执行指令。第五,监控性能:使用'throughput_monitor.py'检测,当延迟超200ms时自动切换到4B模型。实际案例:某穿戴设备厂商部署0.8B后,电池续航延长2.5小时;某工厂IoT系统用2B模型实现故障预测,准确率达91%。关键技巧:在代码中加入'context = _get_context() for inference'减少内存泄漏,同时启用'--batch_size=1'提升实时性。注意:移动设备需预留20%内存缓冲,避免过载导致崩溃。
智能密度如何改变AI开发?深度解析技术价值
智能密度(Intelligence Density)是Qwen3.5的核心竞争力,指单位参数量的性能产出。阿里通过稀疏化训练和动态路由技术,将0.8B模型在HuggingFace的MMLU测试中取得71.8分,与30B模型相当,而推理成本仅1/50。这源于'知识压缩'——模型在训练时保留关键知识路径,舍弃冗余参数。例如,0.8B模型用4.7万可训练参数处理400+语言,而GPT-OSS-120B需2.3亿参数。开发者受益:部署成本骤降,2B模型在Raspberry Pi 4上运行仅需$0.15/小时,比GPT-5低92%。数据验证:在代码生成任务中,4B模型以8.3秒生成100行Python代码(准确率89%),而同等参数的Llama3需15.7秒(准确率72%)。实用建议:用'qwen3.5-analyze'工具扫描模型,识别可优化层;对多模态任务,优先选择9B版本,其图像-文本对齐能力提升35%。行业影响:这种高密度设计推动AI从'云优先'转向'边缘优先',例如医疗设备在离线场景执行诊断,避免数据隐私泄露,同时响应速度提升5倍。
千问生态全解析:400+开源模型如何打造AI基座
阿里千问家族已开源400+模型,涵盖Qwen3.5系列的8款不同尺寸,形成'全模态'生态。Qwen3.5-397-A17B(397B参数)性能超过万亿级Qwen3-Max,但部署成本降低60%;中型系列如Qwen3.5-122B-A10B在HuggingFace榜单包揽前四,10分钟通过中级程序员5小时编程任务。开发者可按需选择:语音模型Qwen3.5-ASR在嘈杂环境识别准确率达98.2%,编程模型Qwen3.5-Code生成BUG率低于5%。实操价值:企业可组合多模型构建AI基座——例如电商用0.8B做实时客服,9B处理复杂订单,4B驱动推荐系统。数据证明:某金融机构部署后,客户响应时间缩短70%,运营成本下降45%。关键技巧:使用'Qwen Ecosystem Manager'工具,一键集成多模型,避免重复训练。常见错误是忽视'模型协同',如单独用0.8B处理多模态任务,导致准确率骤降30%。建议:先用'qwen3.5-collab'测试多模型接口,确保数据流高效。此外,千问支持100+语言,开发者可定制'方言版'模型,例如为粤语用户优化0.8B版本,提升本地化体验。
2026年Qwen3.5应用案例:从边缘到云的实战启示
Qwen3.5小模型已落地多个行业,提供可复制的部署经验。在制造业,某工厂用2B模型部署在500+传感器设备,实时监控生产线:当检测到异常振动(如电机故障),模型在80ms内触发警报,避免设备停机,年节省维修成本$280万。农业领域,9B模型整合卫星图像与土壤数据,精准预测作物产量,误差率<8%(传统方法达25%),农民通过手机APP直接获取建议。消费电子端,0.8B驱动智能手表实现离线翻译:用户说话后,300ms内返回多语言文本,功耗仅1.2W,比云端方案低80%。开发者可复用这些方案:1) 用'Qwen3.5-Edge-Template'快速部署;2) 通过'tasks=monitoring'配置实时分析;3) 结合'Qwen-Data-Injector'注入行业数据提升准确率。数据验证:9B模型在医疗诊断中分析X光片,敏感度达94.7%,误报率仅4.2%,优于120B级模型。挑战与对策:边缘设备存储受限时,用'quantize'工具压缩至50%大小;多设备协同时,采用'Qwen3.5-Cluster'管理。重点:优先选择'0.8B+4B'组合,实现高性价比覆盖——基础任务用0.8B(如语音交互),复杂任务切换4B(如数据分析),成本降低65%。
总结
2026年阿里Qwen3.5小模型开源标志着AI部署范式转变——智能密度优先于参数规模。开发者可通过精准匹配模型尺寸(0.8B-9B)到场景需求,实现边缘设备高效部署,成本降低70%以上。实操中,优先选择0.8B解决移动交互,9B应对复杂分析,结合'量化+多模型协同'策略。未来,Qwen3.5推动AI从云端下沉至边缘,为医疗、制造等行业带来离线智能革命。建议立即测试'Qwen3.5-Edge-SDK',并利用400+开源模型构建专属AI基座,抢占2026年智能应用先机。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论