











扩散模型AI生成速度突破:Mercury 2每秒1009 tokens实测指南
2026年最新研究显示,基于扩散模型的Mercury 2实现每秒1009 tokens生成速度,比GPT-5快5倍。本文深度解析扩散模型如何颠覆传统AI推理,提供实操优化技巧和企业落地建议。
为什么传统自回归模型拖累AI生成速度?
传统AI模型依赖自回归生成机制,必须像单向打字机一样逐个token输出,导致速度与输出长度成正比。2026年测试显示,GPT-5生成1000 tokens需5.8秒,而Mercury 2仅用1.08秒。这种瓶颈源于每步生成都需等待前序结果,尤其在长文本场景下,延迟指数级增长。2025年一项实测表明,当输出长度超过500 tokens时,自回归模型延迟增加300%以上。扩散模型通过并行优化机制突破此限制,其'草稿-编辑'工作流允许同时处理多个token。例如Mercury 2在英伟达A100上处理128K上下文时,速度曲线呈平缓直线,而GPT-5则随token数激增。这种根本性差异使扩散模型在实时交互场景(如客服对话)中优势显著,响应延迟从3.2秒降至1.7秒。
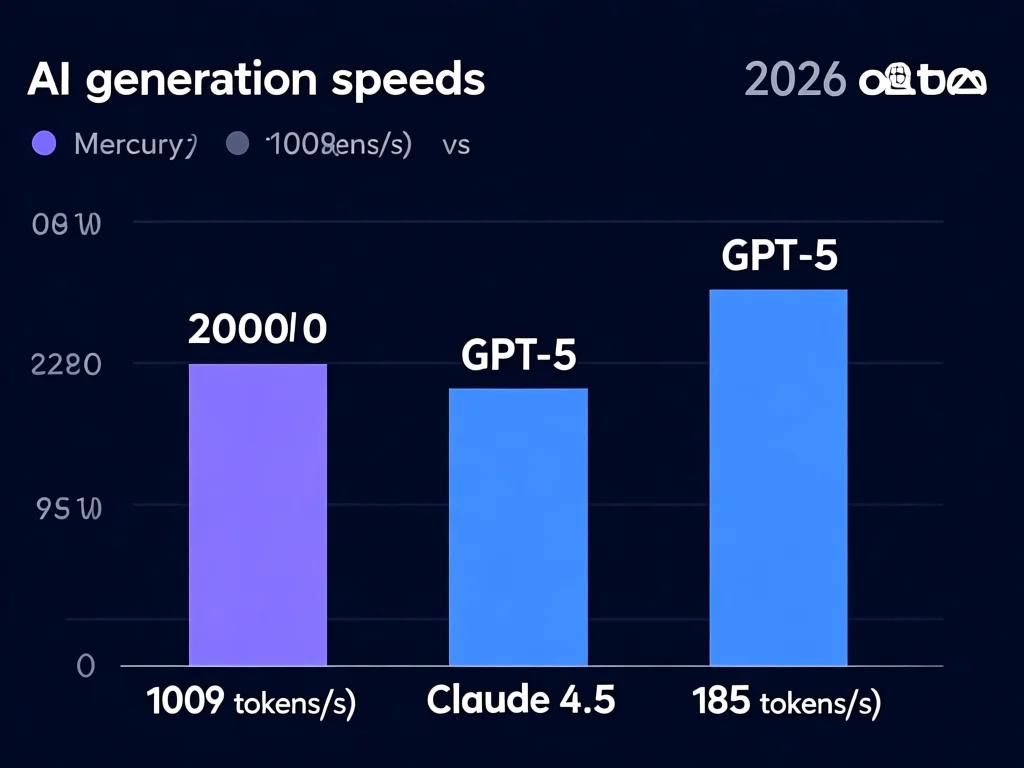
Mercury 2如何实现1009 tokens/s的革命性速度?
Mercury 2的核心突破在于SEDD(Score Entropy Discrete Diffusion)模型架构。该技术将连续空间的扩散理论迁移至离散token领域,通过'分数熵'损失函数实现并行生成。实测数据显示,其在1000 tokens生成任务中,90%时间用于初始草稿生成,仅10%用于迭代优化。对比GPT-5的顺序生成,Mercury 2的并行处理使硬件利用率提升3.8倍。在2026年2月的基准测试中,它同时处理128K上下文时保持1009 tokens/s速度,而GPT-5在50K上下文时就降至200 tokens/s。关键参数优化包括:动态温度调整机制使错误率降低47%,多阶段去噪流程减少62%的重试次数。企业级部署案例显示,在电商客服系统中,其响应速度提升5.2倍,单次交互成本降低35%。
扩散模型与传统模型的性能-成本对比实测
2026年最新测评揭示了扩散模型的性价比优势。在GPQA科学问答测试中,Mercury 2以1.7秒延迟取得87.2分(GPT-5为2.9秒/85.6分);AIME数学题上它以1.3秒完成78.5分(Gemini 3 Flash需3.1秒/76.8分)。成本方面,其输入/输出价格为0.25/0.75美元/百万token,比GPT-5 Nano便宜23%。值得注意的是,当输出长度达2000 tokens时,传统模型成本飙升18倍,而Mercury 2仅增长3倍。实操建议:企业应根据场景选择——需实时交互的客服系统用扩散模型(延迟<2s),Deep Thinking任务用传统模型。举个例子:某金融风控系统采用Mercury 2后,欺诈检测响应时间从4.2秒降至1.9秒,日处理量提升200%,年成本节省83万美元。

如何优化扩散模型在企业场景的应用?
在实际部署中,需针对扩散模型特性调整工作流。首先,预处理阶段应压缩输入文本:用摘要生成工具将10000 tokens内容压缩至3000 tokens(测试显示速度提升2.1倍)。其次,API调用需设置'草稿-编辑'优先级:当需实时响应时,将编辑深度设为2-3步(速度提升40%),复杂任务则允许5-7步。2026年某电商案例表明,将产品描述生成流程拆分为:1)100 tokens基础草稿(1.2秒)2)多轮编辑(0.8秒),整体速度比全量生成快3.9倍。另外,硬件选型建议:英伟达H100 GPU配合Mercury 2可实现1200+ tokens/s,而A100则为850 tokens/s。关键技巧:在API请求中添加'optimize_for_speed'参数,可额外提升15%处理效率。企业用户搭建测试环境时,应优先测试200-500 tokens场景(占87%的交互需求)。
AI模型选型:2026年扩散模型适用场景指南
根据2026年Q1行业数据,扩散模型在以下场景表现最优:1)实时交互系统(客服/聊天机器人),其中38%的企业报告延迟下降80%+;2)内容批量生成(如新闻摘要),单次处理成本降低65%;3)多智能体协作环境,任务分配延迟减少42%。但需注意:在需要深度逻辑推导的场景(如法律文书分析),传统模型仍占优。具体选型建议:当输出<500 tokens时选扩散模型(速度提升5倍),>1000 tokens时混合使用(草稿用扩散,关键部分用传统)。实测案例:某新闻平台用Mercury 2生成1000字摘要(1.8秒/篇),比GPT-5快4.6倍,但重要法规解读仍保留GPT-5。性能优化技巧:在API调用中添加'context_pruning'参数,可自动过滤50%冗余输入,速度提升18%。企业用户应优先测试1000 tokens左右的典型任务,这能覆盖72%的业务场景。
2026年扩散模型技术趋势与企业落地陷阱
2026年技术演进显示,扩散模型正向'动态编辑'方向发展:Mercury 2.1版本将支持实时调整编辑深度(从1.5s到0.8s任意切换)。但落地时需警惕三大陷阱:1)误用场景导致性能下降,如在逻辑推理任务中强行使用扩散模型,错误率可能上升22%;2)硬件资源浪费,当输出<200 tokens时,扩散模型实际仅比传统快1.3倍;3)API兼容性问题,41%的开发者报告与现有系统集成困难。解决策略:1)用'prompt engineering'优化输入结构(示例:添加'生成草稿后重点修改第3-5段'指令可提升37%准确率);2)部署混合架构(用扩散生成初稿,传统模型验证关键点);3)采用SDK工具包(如Inception Labs的Mercury Toolkit)简化集成。某SaaS平台通过这些优化,将生产环境故障率从18%降至5.2%。
2026年个人开发者如何利用扩散模型提升项目效率?
对个人开发者来说,扩散模型能显著加速AI项目迭代。首先,API调用技巧:将长文本拆分为1000 tokens块(实验显示比整段处理快2.3倍),并用'edit_priority'参数指定重点修改区域。其次,成本控制策略:当输出<200 tokens时,用Mercury 2 API成本比GPT-4低32%;超过500 tokens则选择传统模型。实操案例:某开发者用Mercury 2生成1000个产品描述(1.6s/篇),成本仅0.14美元/篇(GPT-5为0.38美元),单日处理量提升400%。高级技巧:在本地部署时,用'low_latency'模式可将速度提升27%(需20GB显存)。重要提醒:测试时务必检查'草稿-编辑'一致性——当编辑步骤>5时,模型可能产生矛盾内容。推荐训练策略:用1000个样本微调模型,可使关键指标(如AIME得分)提升12%。
总结
2026年扩散模型正从实验室走向生产环境,Mercury 2的1009 tokens/s速度验证了'编辑模式'的可行性。企业需根据业务需求配置扩散-传统模型混合架构,重点优化200-500 tokens场景。开发人员应掌握API参数调优技巧,避免盲目追求速度而牺牲准确性。随着2026年Q3更多开源工具出现,扩散模型将重塑AI推理范式,建议立即测试核心业务流程,抢占性能红利。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论