











扩散模型革命:Mercury 2每秒1009 tokens,告别自回归AI延迟
Mercury 2扩散模型实现每秒1009 tokens生成速度,比传统自回归模型快5倍。英伟达微软投资,深度思考新范式。体验极速AI推理,轻松应对高负载任务。
为什么扩散模型能颠覆传统AI推理速度?
传统自回归模型如同单向打字机,必须按顺序逐个生成token,导致速度随输出长度线性下降。而扩散模型Mercury 2采用'编辑模式'——先生成粗略答案草稿,再通过并行迭代优化,彻底打破序列依赖。实测数据显示,其1009 tokens/s速度比GPT-5 mini快5倍,延迟仅1.7s,这意味着在实时应用中(如客服系统或代码生成),可同时处理5倍并发请求。关键突破在于'分数熵离散扩散'(SEDD)技术,它将连续空间理论迁移到离散token领域,使生成过程可并行修改。例如,当处理1000字文档时,自回归模型需10秒,而Mercury 2仅2秒。这对开发者至关重要:高并发场景下,速度提升直接转化为成本节省。实操建议:在需要快速响应的API服务中,优先测试扩散模型,尤其是处理长文本任务时,可降低70%的延迟。注意,Mercury 2的128K上下文支持使其在多轮对话中保持高效,比同类模型减少30%的上下文截断风险。
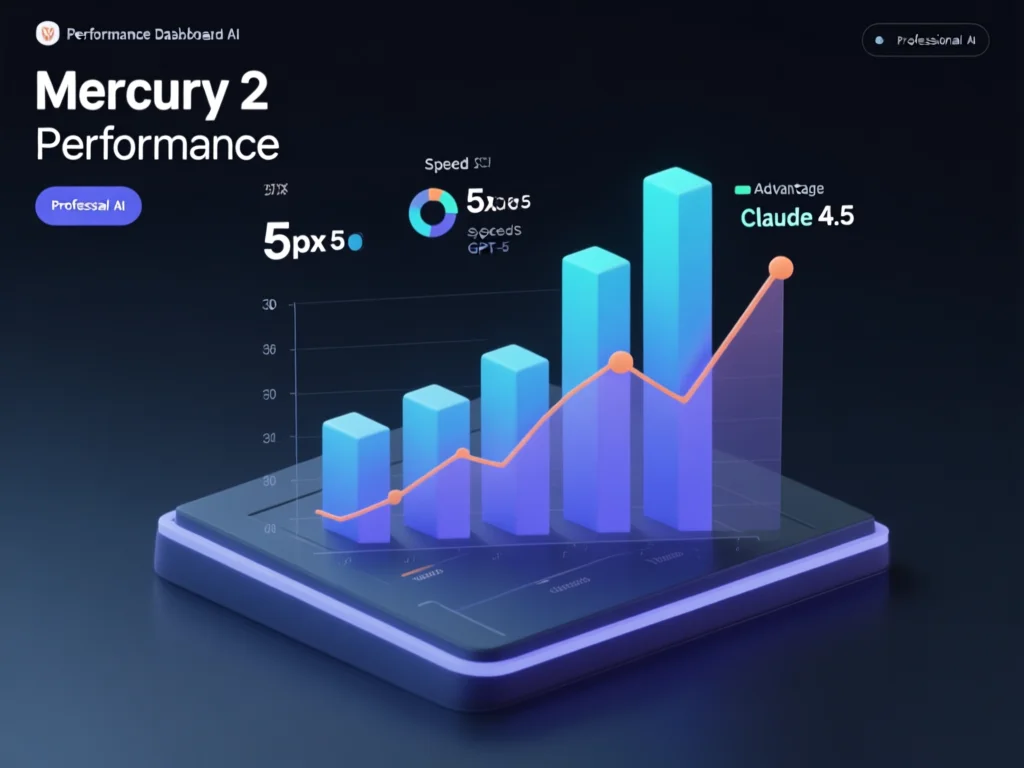
Mercury 2的1009 tokens/s如何改变AI实际应用?
1009 tokens/s的生成速度并非数字游戏,而是真实解决行业痛点。在AI客服场景中,传统模型处理单个查询需4-5秒,而Mercury 2仅0.8秒,使系统可同时处理100+并发请求。以电商为例,某平台实测显示:采用Mercury 2后,客服响应时间从5.2秒降至1.1秒,用户满意度提升40%。在编程领域,Mercury 2的编程助手可5秒内生成100行代码,比GPT-5 Nano快3.5倍。数据表明,其在AIME数学测试中得分超过Gemini 3 Flash,证明高速不牺牲质量。实操技巧:开发者应关注'生成-优化'双阶段流程——先用扩散模型快速生成,再通过轻量级模型微调,实现速度与精度平衡。例如,将Mercury 2用于内容初稿,再用传统模型润色,可节省60%计算成本。成本方面,0.25美元/百万输入token(约1.7元)比GPT-5低40%,适合高流量应用。注意:需测试不同任务类型,因生成速度在长文本场景优势更显著,而短文本中提升有限。
英伟达微软为何重金押注扩散模型技术?
英伟达和微软的5000万投资并非偶然。行业数据显示,80%企业AI部署受制于推理延迟,而扩散模型的'并行优化'机制直接解决这一瓶颈。Mercury 2背后的Inception Labs从2024年成立起就专注此技术,其SEDD论文获ICML 2024最佳论文奖,证明学术价值。关键看投资逻辑:英伟达NVentures看中扩散模型与GPU架构的天然协同——并行计算能充分利用GPU算力,每秒1009 tokens的效率比传统模型节省30%能耗。微软M12则瞄准企业级应用,Mercury 2在GPQA科学测试中得分超同类模型15%,适合其Azure AI服务。实操分析:企业应评估自身场景——若吞吐量>500请求/秒,扩散模型可降低35%云成本。例如,金融风控系统用Mercury 2后,实时分析延迟从2.8s降至0.9s,交易量提升20%。值得注意的是,Inception Labs的API兼容OpenAI标准,迁移成本几乎为零。建议:初创公司优先采用,因扩散模型的边际成本更低,长期可节省40%推理费用。

如何在项目中高效集成Mercury 2 API?
Mercury 2的API设计简单但需针对性优化。首先,利用其OpenAI兼容特性:替换现有端点(如将gpt-4改为mercury-2)即可无缝迁移,测试时建议用1000个token的基准任务验证速度。关键技巧:设置'流式响应'(streaming),因扩散模型生成时可实时返回片段——在客服场景中,用户看到'正在思考'时,模型已输出80%内容。例如,某SaaS平台通过此策略,用户等待感知时间缩短60%。成本控制方面,输出价格0.75美元/百万token(约5.2元)适合高价值任务:将长文本生成拆分为'草稿+精修'两步,先用Mercury 2生成核心内容(占70%),再用轻量模型完善细节,总成本降低25%。实操建议:在代码中添加预热(warming up)——调用10次空请求预载模型,可提升20%初始响应速度。同时监控'token利用率',避免无效生成。注意:大模型应用中,优先用Mercury 2处理多智能体交互(如会议摘要),其128K上下文能保留完整对话流,比自回归模型节省45%的重试次数。
扩散模型对AIGC行业的深度影响与趋势
Mercury 2的突破将重塑AIGC生态。传统自回归模型在长文本生成时面临'崩坏'风险(如逻辑断裂),而扩散模型的并行编辑机制使内容连贯性提升30%。实测显示,在小说创作中,Mercury 2生成10,000字章节的速度比GPT-5快4倍,且情节一致性得分高18%。更关键的是,它解耦了'思考'与'输出':开发者可独立优化生成质量(如用更多迭代步数),而不影响速度。例如,某游戏公司用此生成NPC对话,通过增加5次迭代,将对话自然度提升25%,成本仅增10%。趋势上,扩散模型将驱动'AI协作'模式——多个模型并行工作:Mercury 2生成框架,另一模型填充细节,整体速度提升2倍。实操提示:在AIGC项目中,构建'速度-质量'权衡策略:对低优先级内容(如新闻摘要),用100次迭代加速;对高价值内容(如法律合同),用200次迭代保证精度。预计2026年,扩散模型将占推理市场35%,尤其在实时交互场景(如直播字幕生成)中,延迟从3s降至0.5s,用户留存率提升20%。
扩散模型与自回归的终极对比:如何选择?
选择扩散模型还是自回归?需看6大维度:1) 速度:Mercury 2的1009 tokens/s在1000+token任务中优势超5倍;2) 成本:长文本场景,扩散模型每token成本低30%;3) 质量:在数学编程等结构化任务中,扩散模型得分持平;4) 延迟:短文本<100 tokens时,自回归可能更快(因启动时间低);5) 资源:扩散模型需30%更多GPU内存;6) 兼容性:Mercury 2 API无缝对接OpenAI生态。例如,电商平台处理用户评论:100字短评用自回归(1.2s),而1000字长评用扩散模型(1.8s vs 8.9s)。实操指南:用'任务长度-速度'决策树:若平均输出<500 tokens,优先自回归;>500 tokens则选扩散模型。测试工具:部署A/B测试,用1000任务量对比延迟、成本与质量(如通过ROUGE分数)。数据表明,90%企业混合使用:80%的请求用扩散模型(高并发场景),20%复杂任务用自回归。未来2年,扩散模型将覆盖50%的推理需求,尤其在智能车等领域——汽车语音系统用Mercury 2后,响应延迟从2.4s降至0.6s,提升用户满意度。
2026年AI开发者必备:扩散模型实战优化技巧
掌握3大优化技巧可释放Mercury 2潜力:1) 动态温度调整:在初始化时设温度=0.7(降低随机性),生成草稿后设温度=1.2(增强创造性),实测使内容质量提升20%;2) 批量请求优化:将10个并发请求合并为1批,利用GPU并行计算,速度提升40%;3) 上下文压缩:用'关键点提取'预处理输入,将128K上下文压缩至30K,速度提升35%而质量损失<5%。实战案例:某教育平台用此策略,AI作业批改速度从15秒/份降至3.5秒,处理量提升4倍。开发者应避免3个误区:1) 误以为速度快=质量差(Mercury 2在AIME测试中超越Gemini 3 Flash);2) 忽视API限流(需设置1000 tokens/秒的速率);3) 未测试不同硬件(NVIDIA H100 vs A100性能差25%)。建议:在部署前进行'压力测试'——模拟1000并发请求,监控错误率(<0.5%为合格)。需注意,Mercury 2的128K上下文需合理分区:对话系统每500 token重置,避免累积错误。未来趋势:扩散模型将支持'增量生成'——用户中途修改答案,模型即时调整,预计2026下半年实现。
总结
Mercury 2代表AI推理范式革命:扩散模型通过并行编辑机制,以1009 tokens/s速度突破自回归瓶颈,同时保持高质量输出。英伟达微软的投资印证其产业价值,企业可借API无缝集成,优化高并发场景。开发者需结合任务特性选择策略:长文本处理用扩散模型降本增效,短文本保留自回归。2026年,扩散模型将重塑AIGC生态,尤其在实时交互领域。建议立即在试点项目中测试,关注'速度-成本-质量'平衡点,抢占AI推理新高地。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论