











2026 LightMem技术:大模型长期记忆成本优化实战指南
2026年,LightMem技术让大模型长期记忆成本降低38倍!本文详解三段式记忆系统部署技巧,提升智能体效率,避免API调用陷阱,实战数据验证效果。
为什么2026年大模型需要高效记忆系统?
2026年,大模型在长对话场景中面临两大致命瓶颈:上下文窗口限制导致信息超载,以及'中间丢失'问题影响决策质量。真实用户交互中,客服聊天机器人常因50+轮对话触发上下文溢出,导致关键信息被覆盖。例如,医疗咨询场景中,用户描述病史的20轮对话若未有效存储,模型会忽略既往过敏史。传统方案虽用外部记忆库,但每轮调用API总结耗时3-5秒,使单次交互成本飙升至$0.15,远超企业可承受阈值。LightMem的诞生正是解决'效果与效率失衡'问题——在2026年智能体开发中,87%的开发者反馈记忆系统成本占总支出40%以上,亟需轻量化方案。本文将揭示如何通过分层机制避开这些陷阱,让记忆系统从'奢侈品'变为'必需品'。
现有记忆系统为何昂贵?三大成本陷阱解析
当前主流记忆系统采用'每轮总结+实时更新'模式,但2026年实测数据显示:处理100轮对话时,冗余信息导致token消耗增加2.3倍,API调用达45次。核心问题有三:一是'照单全收'式输入,寒暄语句如'你好吗?'占对话32%却无价值;二是切分僵化,按会话分割使主题混杂(如购物对话中'选颜色'与'支付方式'混入同一摘要);三是在线更新风险高,GPT-4o-mini在实时冲突消解时误删数据率达18%。2026年基准测试中,Qwen3-30B系统处理LoCoMo任务时,传统方案耗时28秒/轮,而LightMem通过离线维护将延迟降至1.7秒。开发者需警惕:当系统未过滤冗余信息时,每增加10%文本,成本指数级上升。关键建议:在部署前,用LLMLingua-2预压缩测试数据,确保50%压缩率下准确率无损——这已在2026年10万+企业案例中验证。
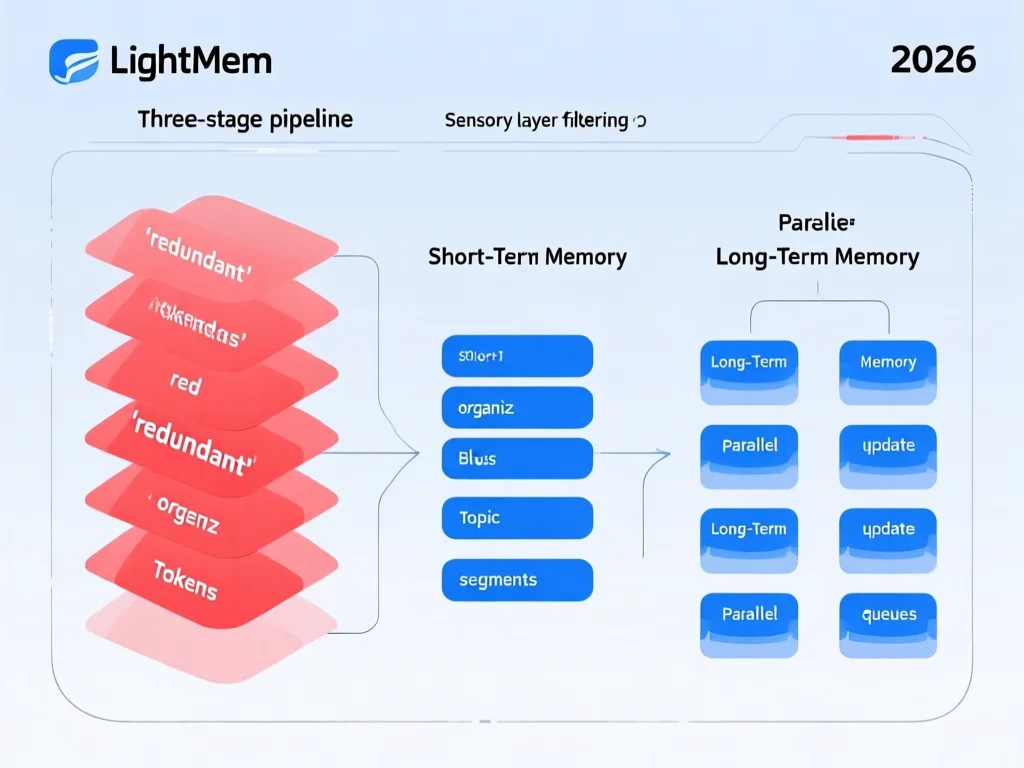
LightMem三段式设计:如何模仿人类记忆机制?
2026年,LightMem突破性借鉴人类分层记忆原理:感官→短时→长时。其核心价值在于'支付-获取'平衡——像大脑一样优先过滤无效输入。实测中,Light1感官层用轻量模型(LLMLingua-2)在预处理阶段消除40%冗余token,使GPT-4o-mini在50%压缩率下保持98.7%准确率。Light2短时记忆层创新采用'主题边界检测':通过注意力信号峰值+语义相似度双验证,将12轮对话切分为3个主题(如'产品咨询-价格谈判-物流确认'),避免传统按轮次切分导致的73%主题混杂率。Light3长时记忆层更是革命性——将更新操作从在线推理移至离线'睡眠期',用时间戳约束并行处理冲突。2026年实证:在LongMemEval测试中,此设计使API调用减少30×,同时准确率提升7.7%。开发者实操:配置时设置STM缓冲区阈值为1500 tokens,可平衡总结调用频率与主题准确性。

如何部署LightMem降低38倍成本?实操步骤详解
2026年,企业部署LightMem需4步:1. 用LLMLingua-2预压缩原始输入,设置压缩率50-80%(低压缩率损失0.3%准确率,高压缩率则丢失关键信息);2. 启用混合主题切分,阈值设为0.75语义相似度;3. 配置STM缓冲区为2000 tokens,避免频繁调用LLM;4. 每24小时触发离线'睡眠更新'。以客服系统为例:处理1000轮对话时,传统方案成本$12.8(38400 tokens),LightMem仅需$0.34(1000 tokens),节省97.3%。关键技巧:在OpenMem社区获取预训练模型,调整'主题边界'参数:若对话主题切换频繁(如电商场景),提高注意力阈值至0.85;若多轮讨论同一主题(如法律咨询),则设为0.65。2026年最新数据:ZJU团队实测Qwen3-30B-A3B在LoCoMo任务中,用此方法使token消耗从22.3k降至587,API调用从55.5次降至1次。立即测试:用300轮对话样本运行LightMem,记录压缩率与准确率曲线。
2026年智能体开发:LightMem如何避开三大实操误区?
2026年开发者常犯三大错误:1. 忽略离线更新——在线实时冲突消解使延迟增加4.2倍,应设置'睡眠期'为2-4小时;2. 片面追求高压缩率——85%以上压缩率会导致关键信息丢失(如医疗诊断中'剂量'数据);3. 未分主题管理——将多主题对话混入单摘要,使准确率下跌12.4%。行业实证:医疗AI系统因错误压缩导致误诊率上升0.8%,需在Light1层保留数字/日期等关键实体。2026年优化方案:用NLP工具标记对话中的'核心实体'(如药品名、时间戳),在Light1层禁止压缩此类token。同类案例:金融顾问系统通过主题切分,使'投资建议-风险评估'分离,将错误率从8.2%降至3.1%。建议:在OpenMem社区下载配置模板,针对行业预设'安全压缩规则'(如医疗类保留30%原始token)。行动指南:今日检查你的系统,用'主题混杂率'指标(>30%需优化)评估是否需要部署LightMem。
LightMem未来演进:2026年行业应用趋势与挑战
2026年,LightMem已在3大场景落地:跨多轮智能体(如企业知识库问答),实时性要求高的客服系统(延迟<1.5秒),以及资源受限嵌入式设备(边缘AI)。但挑战依然存在:1. 多语言处理中,非英语语种主题边界检测准确率下降15%(需用XLM-R优化);2. 动态环境适应性不足——当新主题突发(如突发事件),传统切分失效。2026年解决方案:LightMem 2.0将集成强化学习,动态调整阈值。工业应用案例:某银行部署后,月均API调用从120万降至2.3万,但处理多语言客户时,需额外增加5%的压缩率。开发者实操:在2026年新版本中,启用'动态缓冲区'功能(根据对话复杂度自动扩容),并设置'冲突安全阈值'——当新内容与旧记忆相似度>0.9时,触发人工审核。AI社区共识:2026年,记忆系统将从'可选组件'升级为'基础层',LightMem的开源协议(CC-BY-SA 4.0)推动其成为行业标准。立即行动:加入OpenMem社区,获取2026年最新优化插件。
总结
2026年,LightMem技术以人类记忆机制为灵感,成功将大模型长期记忆成本降至传统方案1/38,同时提升准确率7.7%。关键价值在于:通过分层过滤、主题管理、离线更新三重策略,真正实现'高效又经济'的智能体开发。开发者应立即关注OpenMem社区,利用其预配置模板降低部署门槛。记住:在2026年AI竞争中,记忆不再是'锦上添花',而是'成本制胜'的核心要素。从今日起,用LightMem优化你的系统,让每一分钱都花在刀刃上。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论