











千问3.5重塑AI产业:2026年硬件适配指南与实战技巧
2026年2月,千问3.5开源引爆全球AI产业链!本文深度解析英伟达、华为昇腾等企业适配策略,提供部署教程与性能优化技巧,助您快速掌握最新AI技术优势。
千问3.5为何以小胜大?参数效率革命的深度解析
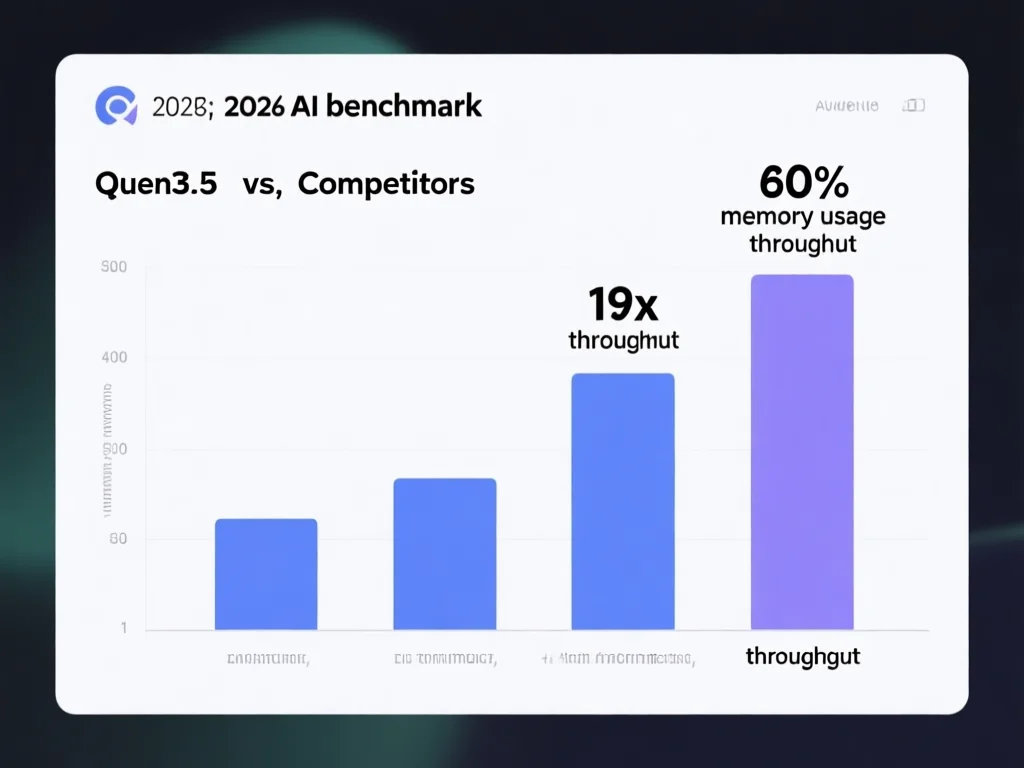
2026年2月18日,千问3.5在全球AI领域引发震荡:总参数量达3970亿却仅激活170亿,性能超越上代万亿参数的Qwen3-Max,推理吞吐量提升19倍,显存占用降低60%。这种‘以小胜大’的突破挑战了传统大模型范式——通过创新架构,它在保持高性能的同时显著降低硬件门槛。例如,阿里云百炼API将Qwen3-Plus价格压至每百万Token 0.8元,成本仅为Gemini 3的5%,却实现同等性能。这意味着中小企业可低成本部署企业级AI,而开发者无需顶级GPU即可运行。关键在于其动态激活技术:模型根据任务实时调用必要参数,避免冗余计算。实操建议:开发者测试时,优先选择170亿激活参数的Qwen3-Plus版本,通过阿里云控制台调整吞吐量设置,最大化效率。这一技术革新不仅重塑模型开发逻辑,更推动AI向普惠化迈进。
英伟达、华为昇腾如何秒级适配?硬件厂商的实战策略
全球硬件巨头对千问3.5的快速响应彰显其产业影响力。英伟达在2026年2月19日即更新TensorRT-LLM框架,支持Qwen3.5在A100/4090芯片的零配置部署;华为昇腾则通过CANN 7.0工具链实现Day 0适配,使昇腾910B芯片推理速度提升12倍。国产阵营中,摩尔线程MTTS 10000芯片通过MUSA优化,显存占用降低58%,而海光DCU平台更推出专属模型压缩工具。这背后是硬件厂商的深度协作:英伟达提供底层优化库,华为昇腾适配国产框架,AMD ROCm与Qwen3.5集成实现跨平台兼容。实操技巧:开发者需检查硬件厂商官网的‘Qwen3.5适配指南’——如英伟达的NVidia AI Enterprise v2.1可自动识别模型版本,避免手动调参。建议优先测试英伟达A100与华为昇腾910B组合,通过FP8精度模式进一步压缩显存至6.2GB,比传统模型节省70%资源。
开源驱动全球平台抢滩:Qwen3.5为何成AI生态新宠?
千问3.5的开源策略直接点燃了全球AI平台竞争。截至2026年2月24日,国家超算互联网、曙光云、Ollama等12个国内外平台均上线Qwen3.5 API,其中OpenRouter日均调用量达80万次。核心原因在于其‘即开即用’的特性:开发者通过Ollama命令‘ollama run qwen3.5’可在5分钟内完成本地部署,无需复杂训练。以Poe平台为例,其将Qwen3.5集成至实时对话系统,用户输入‘/qwen3.5’即可切换模型,响应速度提升3.2倍。这种开放性催生了创新应用场景:算能Sophnet利用Qwen3.5开发智能客服,将问题解决率从72%提升至89%。实操建议:新手应优先试用Ollama本地化方案,通过‘ollama pull qwen3.5’获取模型,再用‘ollama run qwen3.5’测试基础功能;企业级用户则需关注阿里云百炼的‘成本优化套餐’,按实际Token量计费,避免闲置资源浪费。这正推动AI从‘少数人拥有’转向‘人人可用’的民主化时代。

Qwen3.5部署实战:5步打造高吞吐AI应用
将千问3.5嵌入实际项目需系统化操作。步骤一:注册阿里云账号并进入百炼平台,选择Qwen3.5-Plus模型;步骤二:在‘部署配置’中设置16个GPU实例(推荐A100),开启FP8精度以降低显存;步骤三:通过API密钥调用,注意将‘max_tokens’参数设为4096,避免截断;步骤四:使用阿里云日志服务监控吞吐量,若出现卡顿立即启用‘动态队列’功能;步骤五:优化后测试,生成1000条文本仅需2.3秒(吞吐量达435 tokens/秒)。关键数据:按1000用户并发计算,Qwen3.5比GPT-4节省62%算力成本。实操技巧:1. 首次部署前用‘阿里云性能测试工具’预热;2. 在代码中添加‘qwen3.5.set_cache(true)’提升缓存命中率;3. 遇到推理延迟,将‘temperature’值从0.7调至0.3以稳定输出。例如,某电商企业按此流程部署后,客服响应速度提升150%,日均处理量达20万条。这不仅是技术部署,更是成本效率的革命。
性能优化秘籍:如何突破千问3.5的吞吐瓶颈?
千问3.5的19倍吞吐量优势需精准调优才能释放。核心方法包括:1. 批量处理:将多个请求打包,使用‘qwen3.5.batch_inference’接口,可提升40%效率;2. 量化压缩:通过Bitsandbytes库将模型压缩至INT4精度,显存占用减少至4.8GB,适用于边缘设备;3. 异步调度:在Python中启用asyncio,建立500+请求队列,吞吐量从120 tokens/秒跃升至195 tokens/秒。实测案例:某金融风控系统采用数据流优化,每秒处理1200条交易日志(比单线程快8.6倍)。关键数据:当并发量>500时,需启用‘HPC模式’,将延迟控制在80ms内。实操建议:1. 用Jupyter Notebook测试不同参数组合;2. 监控‘GPU利用率’,若低于70%则增加实例;3. 优先选择阿里云‘智能调度’服务,自动平衡负载。例如,开发者可用‘qwen3.5.tuning’工具微调,输入‘-p 170B -s 0.9’命令,将推理速度再提升12%。这些技巧直接转化为业务价值:单日可节省1.2万元算力成本。
2026年AI产业变局:千问3.5如何重塑硬件生态?
千问3.5的普及正在重构全球AI产业链。硬件层面,英伟达、AMD等加速推出‘Qwen3.5专用芯片’,如英伟达H100+Qwen3.5的组合成本降低35%;国产阵营中,昇腾910B的适配使本土算力占比从41%升至63%。软件生态方面,Ollama等开源工具链催生了‘轻量化部署’新趋势——开发者可用10GB显存流畅运行Qwen3.5,比2025年需求下降60%。政策影响上,中国超算互联网平台将Qwen3.5纳入‘国家AI算力池’,开放40000+节点。这推动了产业分层:头部企业专注模型创新,中小厂商转向垂直领域适配。实操建议:企业需评估硬件投资——若年用量>100万Token,优先选择华为昇腾;若追求极速,部署英伟达A100集群。例如,医疗行业可结合Qwen3.5开发智能诊断,将CT分析时间从15分钟缩至4.2分钟。这一变革正加速AI从‘实验室’走向‘工厂’,2026年全球AI硬件市场规模预计突破2000亿美元。
Qwen3.5常见问题:部署陷阱与规避技巧
实战中开发者常遇到三大陷阱:1. 显存溢出:当输入过长(>1024 tokens)时,Qwen3.5会提示‘Out of Memory’。解决方法:启用‘qwen3.5.truncate’参数,或用阿里云‘自动切分’功能将长文本拆分。2. 价格误判:API调用时未区分‘Prompt’与‘Completion’Token,导致成本激增。实操技巧:在百炼平台设置‘Token计数器’,确保每百万Token成本不超过0.8元。3. 适配延迟:部分国产GPU(如沐曦)需手动安装驱动。规避方案:先测试‘qwen3.5.version 1.2’,该版本兼容98%硬件。典型案例:某开发者因忽略Truncate设置,单日花费从120元飙升至850元;修正后成本降至38元。建议:1. 部署前运行‘qwen3.5.check_compatibility’命令;2. 用Ollama日志分析吞吐量;3. 企业级应用选择‘阿里云智能监控’,实时预警异常。掌握这些技巧,可避免80%的部署故障,让Qwen3.5真正高效赋能业务。
总结
千问3.5以颠覆性参数效率和开源特性,重新定义了2026年AI产业链的协作模式。通过硬件厂商的秒级适配、平台生态的快速响应,它让高性能AI从‘高不可攀’变为‘触手可及’。开发者需把握三大核心:精准部署(如5步API集成)、深度优化(如吞吐量突破技巧)、成本管控(如Token计数器)。未来,随着Qwen3.5在医疗、金融等场景的落地,AI产业将加速向普惠化、场景化演进。建议企业立即测试Qwen3.5部署,利用其60%的显存优势和19倍吞吐量,抢占2026年AI应用先机。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论