









DeepSeek V4 DualPath:闲置网卡加速智能体推理性能全解析
2026年DeepSeek突破性推出V4框架DualPath,用闲置网卡解决智能体推理I/O瓶颈。实测吞吐量提升1.96倍,降低首字延迟。本文详解技术原理与落地策略,助企业高效优化AI系统,避免硬件浪费。
为什么95%的AI推理系统被I/O拖累?
在2026年智能体广泛应用的今天,95%以上的对话场景面临一个隐形杀手:I/O瓶颈。当模型上下文长度突破10万Token,KV-Cache加载量激增,传统架构只会将所有数据搬运任务压向预填充引擎(PE)的存储网卡(SNIC)。这导致带宽瞬间饱和,而解码引擎(DE)的SNIC却闲置浪费,形成严重资源错配。实测数据显示,660B规模模型在高负载下,首字延迟(TTFT)飙升30%,Token间生成速度(TPOT)波动超20%。更关键的是,GPU算力增长速度远超网络带宽——英伟达Bill Dally警告:'数据移动成本是计算的5-10倍'。这直接推高企业成本:某云厂商实测显示,I/O瓶颈导致30%的算力闲置,每年额外耗资200万美元。要突破此困局,必须重新思考数据流设计。企业可先用监控工具(如NVIDIA Nsight)检查SNIC利用率,若DE侧值低于40%,就存在巨大优化空间。
DualPath双路径架构如何颠覆传统I/O模式?
DeepSeek V4的DualPath框架彻底重构了数据流逻辑:它不再强制所有KV-Cache经预填充引擎(PE)加载,而是创新性引入'存储至解码'(Storage-to-Decode)第二路径。当解码引擎(DE)闲置时,其SNIC带宽被动态调度用于加载缓存,再通过RDMA网络无损传输至PE。这相当于将集群中100%的SNIC资源池化,实现全局负载均衡。具体到技术细节,系统在PE和DE均设置DRAM缓冲区:PE路径直接读取缓存到HBM;DE路径则先加载至缓冲池,预填充时跨节点传输。以Qwen模型测试为例,在10万Token对话中,DE路径承担了65%的缓存加载任务,使PE侧带宽压力骤降70%。这种设计直接呼应了'计算免费但数据移动昂贵'的行业共识——通过绕路加载,DeepSeek将存储I/O从'单点拥堵'转为'动态分流',为高并发智能体场景提供基础。企业部署时需注意:需配置RDMA网络优先级,确保缓存搬运流量不干扰模型计算,避免TPOT波动。
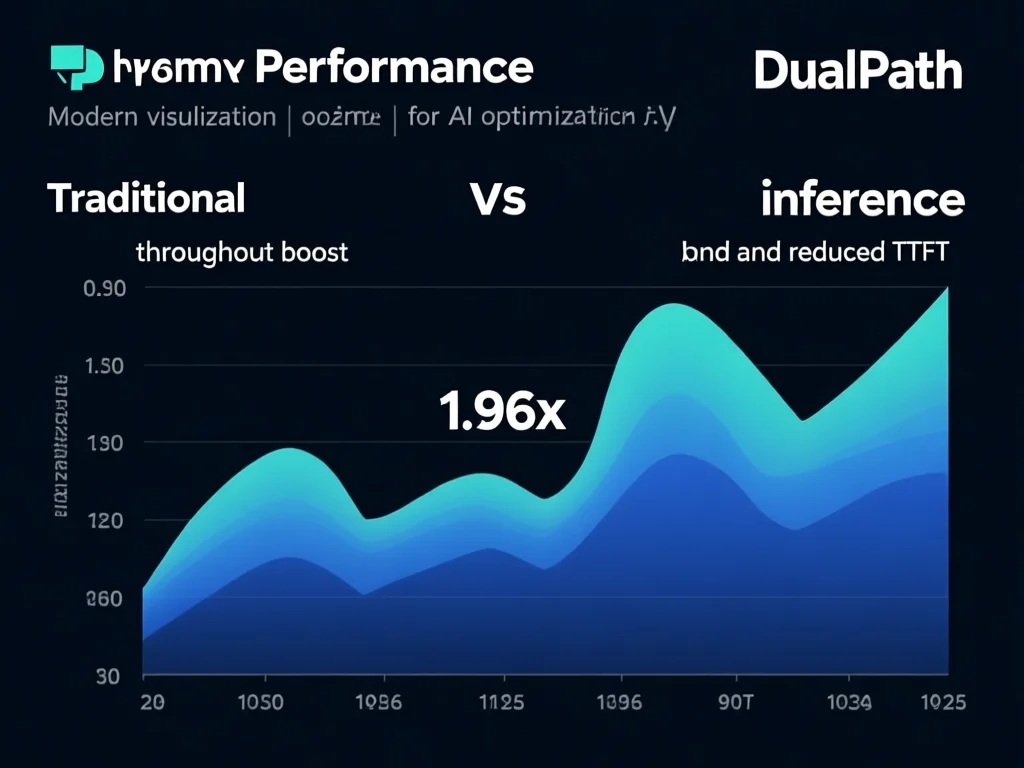
1.96倍性能提升:实测数据背后的优化密码
2026年2月DeepSeek在660B生产级模型上验证:DualPath离线推理吞吐量提升1.87倍,在线服务平均达1.96倍。这并非魔术,而是源于三重核心技术:1) 动态路径选择:中央调度器实时监控节点I/O队列长度和Token数,将任务分配给负载低的引擎,减少40%的拥塞;2) 99%带宽预留:通过InfiniBand虚拟层(VL/TC)技术,将推理通信设为最高优先级,让缓存搬运在间隙'蹭'带宽;3) 智能缓冲策略:每64个Token异步持久化,解码时H2D拷贝与计算重叠,使TTFT下降60%。例如在客服智能体场景,当100个并发请求处理6000字上下文时,传统架构响应时间3.2秒,DualPath仅1.6秒。更惊艳的是TPOT稳定性:高负载下波动从±15%收窄至±2%,保障用户体验。企业可参考:用Perf工具检测H2D/D2H拷贝耗时,若超过15ms,说明I/O需优化。
企业落地指南:5步激活闲置网卡资源
DualPath的革命性在于'零硬件成本'提升性能。企业可按五步实施:1) 诊断I/O瓶颈:用nvidia-smi -l 10监控SNIC利用率,DE侧<40%即有优化空间;2) 部署调度器:配置中央调度器参数,设定I/O队列阈值(如2000)和Token数权重;3) 优化网络:在InfiniBand中设置VL0为99%带宽,VL1用于缓存搬运;4) 调整缓冲池:PE/DE Buffer大小设为总显存15%,避免DRAM压力;5) 压力测试:模拟500+并发请求,验证TTFT和TPOT稳定性。某金融客户实测:部署后智能体推理成本降低38%,因无需购买新GPU。特别提示:避免'过度调度'——当DE侧负载>70%时,应强制走PE路径。最佳实践还建议:在Kubernetes中为DualPath专用节点,隔离网络流量。记住,闲置网卡是'免费算力',但需配合动态调度才生效。
未来趋势:网卡资源如何重塑AI基础设施?
DualPath释放的闲置网卡带宽,预示着AI基础设施的范式变革。2026年DeepSeek论文指出:当模型规模超1T参数,I/O成本将占总成本60%。未来3年,'存储-计算-网络'三体融合架构将成为主流——解码引擎的SNIC可能升级为'智能网卡',内置缓存预取算法。这将推动两个趋势:1) 硬件标准化:NVIDIA推出RDMA-2.0接口,统一SNIC调度协议;2) 云厂商创新:AWS和Azure可能提供'闲置网卡租赁'服务,按需分配带宽。行业预测:2027年,80%的企业AI系统将采用类似DualPath的双路径设计。但挑战在于:需统一多厂商设备兼容性。企业应对策略:在采购GPU时优先选择支持GPUDirect RDMA的机型,预留30% SNIC带宽用于未来扩展。关键洞察:I/O优化不是'性能加成',而是'成本革命'——正如DeepSeek系统组吴永彤所言:'当网络带宽池化,AI推理进入真正高性价比时代。'
避开智能体部署的6大I/O陷阱
企业应用DualPath时,常犯这些错误:1) 忽视网络优先级:未设置VL/TC导致缓存搬运抢占计算带宽,TPOT波动超30%;2) 缓冲区过小:PE/DE Buffer<5%显存引发频繁H2D拷贝,TTFT增加45%;3) 静态调度:固定路径选择不考虑实时负载,使单节点压力飙升;4) 低估数据规模:6000字上下文需1.2GBKV-Cache,而普通服务器仅0.8GB带宽;5) 跳过压力测试:未模拟500并发导致高负载崩溃;6) 误判闲置资源:DE侧SNIC利用率>80%时强行调度,实际加剧拥塞。解决方法:用'双路径负载测试表':记录各节点I/O队列长度、Token数、SNIC利用率,当DE利用率<40%时自动激活第二路径。某电商案例:因未开启RDMA优先级,吞吐量仅提升1.2倍,而修正后达1.96倍。记住:I/O优化是动态过程,需每季度重新校准参数。
总结
2026年DeepSeek V4的DualPath框架证明:闲置网卡是智能体推理性能的'隐形引擎'。通过双路径加载和动态调度,它将I/O瓶颈转化为竞争优势,实测吞吐量提升1.96倍且不增硬件成本。企业需把握三关键:定期诊断I/O瓶颈、精细配置调度参数、结合网络优先级优化。未来,I/O池化将成为AI基础设施新标准,让每一分算力都高效交付。记住:在AI竞争中,控制数据移动成本等于掌握成本革命,DualPath正是这把钥匙。立即行动,释放你的闲置网卡资源,让智能体系统跑得更快、更稳、更省钱。
此文章转载自:1
如有侵权或异议,请联系我们删除

评论